从音频分析到视觉渲染的全栈工程实践
想要做什么事❓
要做的是什么事儿呢,总结一句话就是:从音频分析到视觉渲染的全栈工程实践
本身的想法是我想做一个短视频,用后摇(Post-Rock)根据音频的生成波浪线或者各种五彩缤纷的形状跟着音频频率跳动,但是这样持续播3-6分钟又感觉有点单调,所以得加点市井生活的视频素材,闲鱼一分钱几百条素材,用程序来实现最终合成视频,加素材就涉及到素材的裁剪卡点,所以我让Deepseek帮我想一个好的方案。
DeepSeek 原方案是一个 Python CLI 脚本,核心逻辑正确(librosa 音频分析 → 动态图形 → 素材卡点 → 合成),但存在三个根本性问题:
- matplotlib 渲染极慢(30-75 分钟出一个 5 分钟视频)
- 没有预览能力(必须渲染完才能看效果,调参周期极长)
- 纯脚本,不可复用(每次改参数都要改代码)
Web 工程化的核心价值:把”跑一次脚本等半小时”变成”浏览器里实时预览、拖拖滑块、满意了一键出片”。
为什么做这件事
后摇(Post-Rock)是一种情绪密度极高的音乐类型:没有歌词,全靠器乐构建从宁静到爆发的张力弧线。这类音乐特别适合做视觉化——因为它的结构天然具有”叙事性”,静谧段落搭配空镜,高潮段落叠加视觉冲击,回落段留白。
传统做法是在 After Effects 或 Premiere 里手动踩点剪辑,一首 6 分钟的曲子至少需要半天。我想做的是:把”听音乐→感知情绪→选画面→踩节拍”这个过程工程化,让代码完成 80% 的工作,人只需要微调参数。
核心思路:三级音频分析驱动一切
整个系统的灵魂在于音频分析。不是简单地检测节拍,而是做三个层级的分析:
宏观层(Structural):用 MFCC + 聚类算法(agglomerative clustering)把整首歌切成 4-8 个结构段——前奏、铺垫、高潮、回落。每段自动标记情绪标签。
中观层(Rhythmic):节拍检测(beat tracking)+ 起音检测(onset detection),生成所有”切换点”。这些点就是视觉画面可以切换的时刻。
微观层(Frame-level):每一帧计算 RMS 能量和频谱质心。前者控制视觉元素的幅度/亮度/大小,后者控制色彩(低频偏暖,高频偏冷)。
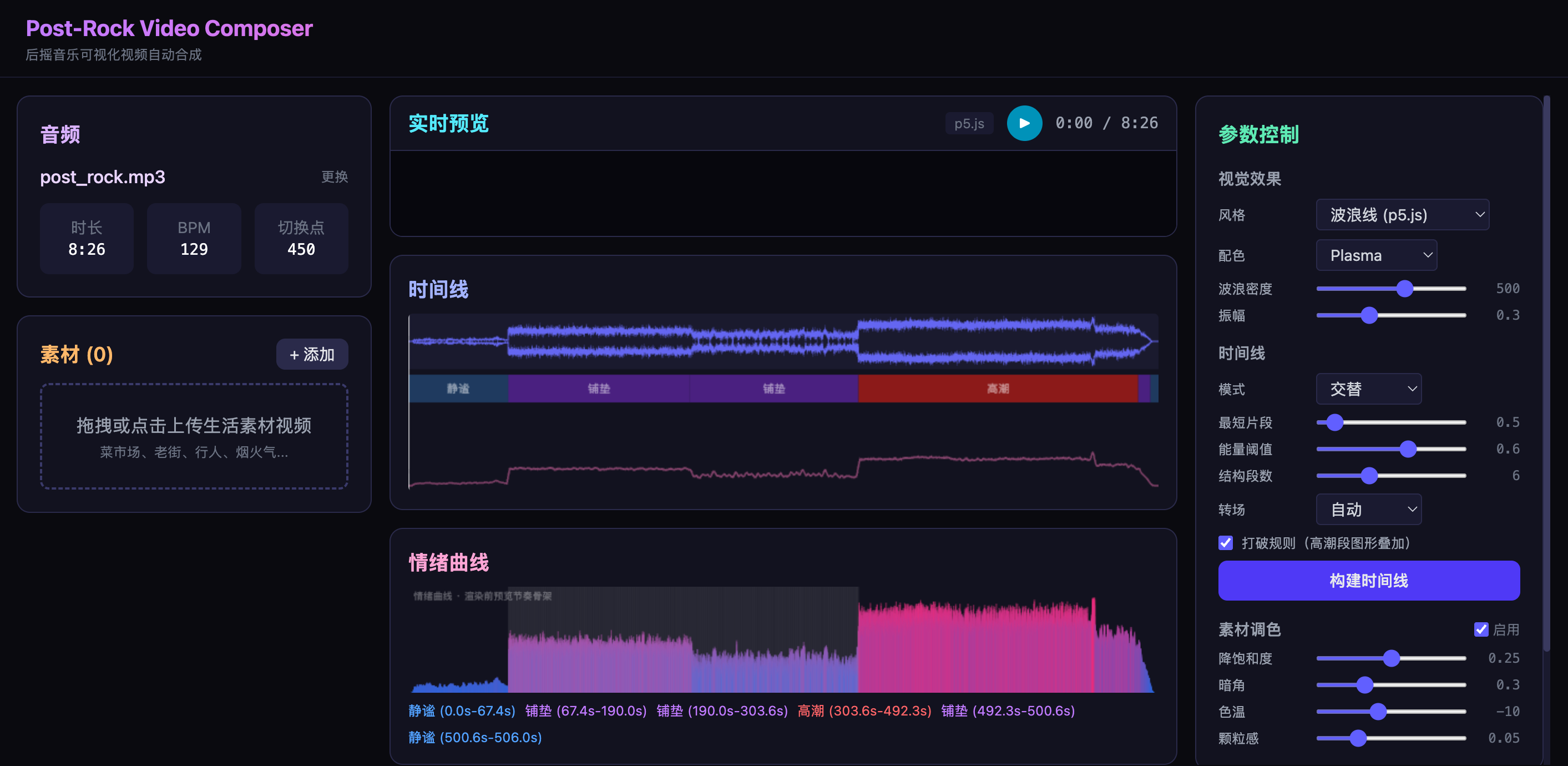
三级分析的结果汇总成一条”情绪曲线”——一个归一化的浮点数组,描述了整首歌每一帧的紧张度。这条曲线是后续所有视觉决策的基础。
整体架构
┌─────────────────────────────────────────────────────┐
│ React 前端 (Vite) │
│ │
│ ┌───────────┐ ┌──────────┐ ┌─────────────────────┐│
│ │ 音频上传 │ │ 素材管理 │ │ p5.js 实时预览画布 ││
│ │ + 波形展示 │ │ + 标签 │ │ (音频驱动可视化) ││
│ └─────┬─────┘ └────┬─────┘ └──────────┬──────────┘│
│ │ │ │ │
│ ┌─────┴────────────┴───────────────────┴─────────┐│
│ │ 时间线编辑器 (可视化波形+段落) ││
│ └─────────────────────┬───────────────────────────┘│
│ │ │
│ ┌─────────────────────┴───────────────────────────┐│
│ │ 参数控制面板 (视觉风格/配色/转场/阈值) ││
│ └─────────────────────┬───────────────────────────┘│
│ │ │
│ ┌─────────────────────┴───────────────────────────┐│
│ │ 渲染导出 (一键渲染 + 进度条 + 下载) ││
│ └─────────────────────────────────────────────────┘│
└──────────────────────┬──────────────────────────────┘
│ REST API + WebSocket
┌──────────────────────┴──────────────────────────────┐
│ Python 后端 (FastAPI) │
│ │
│ ┌────────────┐ ┌────────────┐ ┌──────────────────┐│
│ │ 音频分析 │ │ 素材管理 │ │ 时间线引擎 ││
│ │ librosa │ │ FFmpeg │ │ (交替/叠加/混合) ││
│ │ 三级分析 │ │ 缩略图提取 │ │ ││
│ └─────┬──────┘ └─────┬──────┘ └────────┬─────────┘│
│ │ │ │ │
│ ┌─────┴──────────────┴──────────────────┴─────────┐│
│ │ 视频渲染引擎 (OpenCV + FFmpeg) ││
│ │ 逐帧渲染图形 → 素材裁剪合成 → 加音频输出 ││
│ │ WebSocket 推送渲染进度 ││
│ └─────────────────────────────────────────────────┘│
│ │
│ uploads/music/ uploads/footage/ output/ │
└─────────────────────────────────────────────────────┘
技术栈
后端
- 框架: FastAPI (异步、现代、自带 OpenAPI 文档)
- 音频分析: librosa (节拍/onset/RMS/频谱质心/结构分段)
- 视频处理: OpenCV (逐帧渲染图形) + FFmpeg (合成编码)
- 实时通信: WebSocket (渲染进度推送)
- 数据模型: Pydantic v2
前端
- 框架: React 19 + TypeScript + Vite
- UI: Tailwind CSS + shadcn/ui
- 音频可视化: p5.js (WebGL 模式,Phase 1) / Three.js (Phase 2 升级)
- 音频播放+分析: Tone.js 或 Web Audio API
- 波形展示: wavesurfer.js (时间线编辑器中的波形)
- 状态管理: Zustand
- HTTP 客户端: 原生 fetch 或 ky
项目目录结构
post-video/
├── backend/
│ ├── main.py # FastAPI 入口
│ ├── requirements.txt
│ ├── api/
│ │ ├── audio.py # POST /audio/upload, GET /audio/analysis
│ │ ├── footage.py # POST /footage/upload, GET /footage/list, DELETE
│ │ ├── timeline.py # POST /timeline/build, PUT /timeline/update
│ │ ├── render.py # POST /render/start, GET /render/status
│ │ └── ws.py # WebSocket /ws/render-progress
│ ├── services/
│ │ ├── audio_analyzer.py # librosa 三级分析
│ │ ├── timeline_builder.py # 交替时间线构建
│ │ ├── footage_manager.py # 素材扫描/缩略图/标签
│ │ ├── video_renderer.py # OpenCV 逐帧渲染 + 合成
│ │ └── ffmpeg_utils.py # FFmpeg 封装
│ ├── models/
│ │ ├── audio.py # AudioFeatures, AnalysisResult
│ │ ├── timeline.py # Segment, Timeline
│ │ └── project.py # ProjectConfig
│ └── core/
│ ├── config.py # 配置加载
│ └── visuals/
│ ├── base.py # 渲染器基类
│ ├── wave.py # 波浪线渲染器
│ ├── particles.py # 粒子渲染器 (Phase 2)
│ └── effects.py # 后处理效果
│
├── frontend/
│ ├── package.json
│ ├── vite.config.ts
│ ├── tsconfig.json
│ ├── tailwind.config.ts
│ ├── src/
│ │ ├── App.tsx
│ │ ├── main.tsx
│ │ ├── pages/
│ │ │ ├── ProjectPage.tsx # 主工作页面(单页应用)
│ │ │ └── Layout.tsx
│ │ ├── components/
│ │ │ ├── AudioUploader.tsx # 音频上传+波形
│ │ │ ├── FootageGrid.tsx # 素材网格管理
│ │ │ ├── PreviewCanvas.tsx # p5.js 实时预览
│ │ │ ├── TimelineEditor.tsx # 可视化时间线编辑
│ │ │ ├── ControlPanel.tsx # 参数滑块面板
│ │ │ ├── RenderPanel.tsx # 渲染导出+进度
│ │ │ └── EnergyChart.tsx # 情绪曲线可视化
│ │ ├── sketches/
│ │ │ ├── waveSketch.ts # p5.js 波浪线 sketch
│ │ │ ├── particleSketch.ts # p5.js 粒子 sketch (Phase 2)
│ │ │ └── types.ts # 可视化参数类型
│ │ ├── stores/
│ │ │ └── projectStore.ts # Zustand 全局状态
│ │ ├── api/
│ │ │ └── client.ts # 后端 API 封装
│ │ └── lib/
│ │ └── audioAnalysis.ts # Web Audio API 辅助
│ └── public/
│
├── uploads/ # 用户上传文件(gitignore)
│ ├── music/
│ └── footage/
├── output/ # 渲染输出(gitignore)
└── README.md详细实施步骤
Phase 1:后端核心(音频分析 + 素材管理 + 渲染引擎)
Step 1.1 - 后端项目初始化
backend/requirements.txt:
fastapi>=0.115
uvicorn[standard]
python-multipart
librosa>=0.10
numpy
opencv-python-headless
pydantic>=2.0
websockets
aiofiles
tqdmbackend/main.py 启动 FastAPI 应用,挂载 CORS、静态文件服务、路由。
Step 1.2 - 音频分析 API
三级分析体系(比 DeepSeek 方案多了结构分段):
# backend/services/audio_analyzer.py
class AudioAnalyzer:
def analyze(self, path: str, fps: int = 30) -> AnalysisResult:
y, sr = librosa.load(path)
# 宏观层:结构分段(intro/build/climax/outro)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
bounds = librosa.segment.agglomerative(mfcc, k=6)
structure_times = librosa.frames_to_time(bounds, sr=sr)
# 中观层:节拍 + onset
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
onset_frames = librosa.onset.onset_detect(y=y, sr=sr, backtrack=True)
onset_times = librosa.frames_to_time(onset_frames, sr=sr)
# 微观层:逐帧特征
hop = int(sr / fps)
rms = librosa.feature.rms(y=y, hop_length=hop)[0]
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr, hop_length=hop)[0]
# 合并切换点 + 过滤过短间距
cut_points = merge_and_filter(beat_times, onset_times, min_gap=0.5)
return AnalysisResult(
duration=len(y)/sr, tempo=tempo,
structure_bounds=structure_times,
cut_points=cut_points,
rms=rms.tolist(),
spectral_centroid=spec_cent.tolist(),
beat_times=beat_times.tolist(),
onset_times=onset_times.tolist()
)API 端点:
POST /api/audio/upload- 上传音频文件,触发分析,返回分析结果 JSONGET /api/audio/analysis/{id}- 获取已分析的结果(带缓存)GET /api/audio/waveform/{id}- 返回音频波形数据(前端绘制用)
Step 1.3 - 素材管理 API
# backend/services/footage_manager.py
class FootageManager:
def scan_dir(self, dir_path) -> list[FootageInfo]:
"""扫描素材目录,提取每个视频的时长、分辨率、缩略图"""
def extract_thumbnail(self, video_path) -> str:
"""用 FFmpeg 提取中间帧作为缩略图"""
def get_frames(self, video_path, start, duration, fps) -> Iterator[np.ndarray]:
"""逐帧读取指定时间段的视频帧"""API 端点:
POST /api/footage/upload- 上传素材视频GET /api/footage/list- 列出所有素材(含缩略图URL、时长、标签)PUT /api/footage/{id}/tag- 设置情绪标签(calm/building/intense/release)DELETE /api/footage/{id}- 删除素材
Step 1.4 - 时间线引擎
# backend/services/timeline_builder.py
class TimelineBuilder:
def build(self, analysis: AnalysisResult, config: TimelineConfig) -> Timeline:
segments = []
for i, (start, end) in enumerate(pairwise(analysis.cut_points)):
# 交替分配
seg_type = "shape" if i % 2 == 0 else "life"
# 能量驱动覆盖(可选)
if config.energy_driven:
avg_e = self.avg_energy(analysis.rms, start, end)
if avg_e > config.energy_threshold:
seg_type = "life"
segments.append(Segment(start=start, end=end, type=seg_type))
return Timeline(segments=segments)API 端点:
POST /api/timeline/build- 根据分析结果 + 配置参数构建时间线PUT /api/timeline/update- 手动编辑时间线(拖拽调整段落边界/类型)GET /api/timeline/{id}- 获取当前时间线
Step 1.5 - 视频渲染引擎
# backend/services/video_renderer.py
class VideoRenderer:
async def render(self, timeline, analysis, config, ws_callback=None):
writer = cv2.VideoWriter(temp_path, fourcc, fps, (w, h))
total_frames = int(analysis.duration * fps)
rendered = 0
for seg in timeline.segments:
if seg.type == "shape":
for t in frame_times(seg.start, seg.end, fps):
frame = self.visual_renderer.render_frame(t, analysis)
writer.write(frame)
rendered += 1
if ws_callback and rendered % 30 == 0:
await ws_callback(rendered / total_frames)
else:
for frame in footage_mgr.get_frames(seg):
frame = self.apply_color_grade(frame) # 统一调色
writer.write(frame)
rendered += 1
writer.release()
# FFmpeg 合成音频
self.ffmpeg_merge(temp_path, audio_path, output_path)
return output_pathAPI 端点:
POST /api/render/start- 启动渲染任务(异步)GET /api/render/status/{job_id}- 查询渲染状态GET /api/render/download/{job_id}- 下载渲染结果WebSocket /ws/render/{job_id}- 实时推送渲染进度
Phase 2:前端 UI
Step 2.1 - 前端项目初始化
npm create vite@latest frontend -- --template react-ts
cd frontend
npm install tailwindcss @tailwindcss/vite
npx shadcn@latest init
npm install p5 @types/p5 wavesurfer.js zustand toneStep 2.2 - 主工作页面布局
单页应用,上下分区:
┌─────────────────────────────────────────────────┐
│ 顶部:音频上传 + 项目标题 │
├────────────────────┬────────────────────────────┤
│ │ │
│ 左侧: │ 右侧: │
│ 素材管理网格 │ p5.js 实时预览画布 │
│ (拖拽上传+标签) │ (音频可视化动态图形) │
│ │ │
├────────────────────┴────────────────────────────┤
│ 中间:时间线编辑器 │
│ [波形 + 彩色段落标注 + 拖拽调整] │
├─────────────────────────────────────────────────┤
│ 底部:参数控制面板 │
│ [视觉风格 | 配色 | 转场 | 能量阈值 | 最短时长] │
│ [渲染导出按钮 + 进度条] │
└─────────────────────────────────────────────────┘Step 2.3 - p5.js 实时预览画布
这是前端的核心组件。p5.js sketch 读取当前音频播放时间点的分析数据,实时渲染可视化:
// frontend/src/sketches/waveSketch.ts
export function createWaveSketch(analysisData: AnalysisData) {
return (p: p5) => {
p.setup = () => {
p.createCanvas(800, 450, p.WEBGL);
};
p.draw = () => {
const t = getCurrentAudioTime();
const frameIdx = Math.floor(t * 30);
const energy = analysisData.rms[frameIdx] / maxRms;
const centroid = analysisData.spectralCentroid[frameIdx];
p.background(10, 10, 15);
// 波浪线
p.beginShape();
p.noFill();
p.stroke(energyToColor(centroid, energy));
p.strokeWeight(3);
for (let x = -400; x < 400; x += 2) {
const freqMod = 0.5 + 2 * energy;
const y = Math.sin(x * freqMod * 0.01) * energy * 200;
p.vertex(x, y);
}
p.endShape();
// 散点/粒子
for (let x = -400; x < 400; x += 40) {
const y = Math.sin(x * (0.5 + 2*energy) * 0.01) * energy * 200;
p.circle(x, y, 8 * energy);
}
};
};
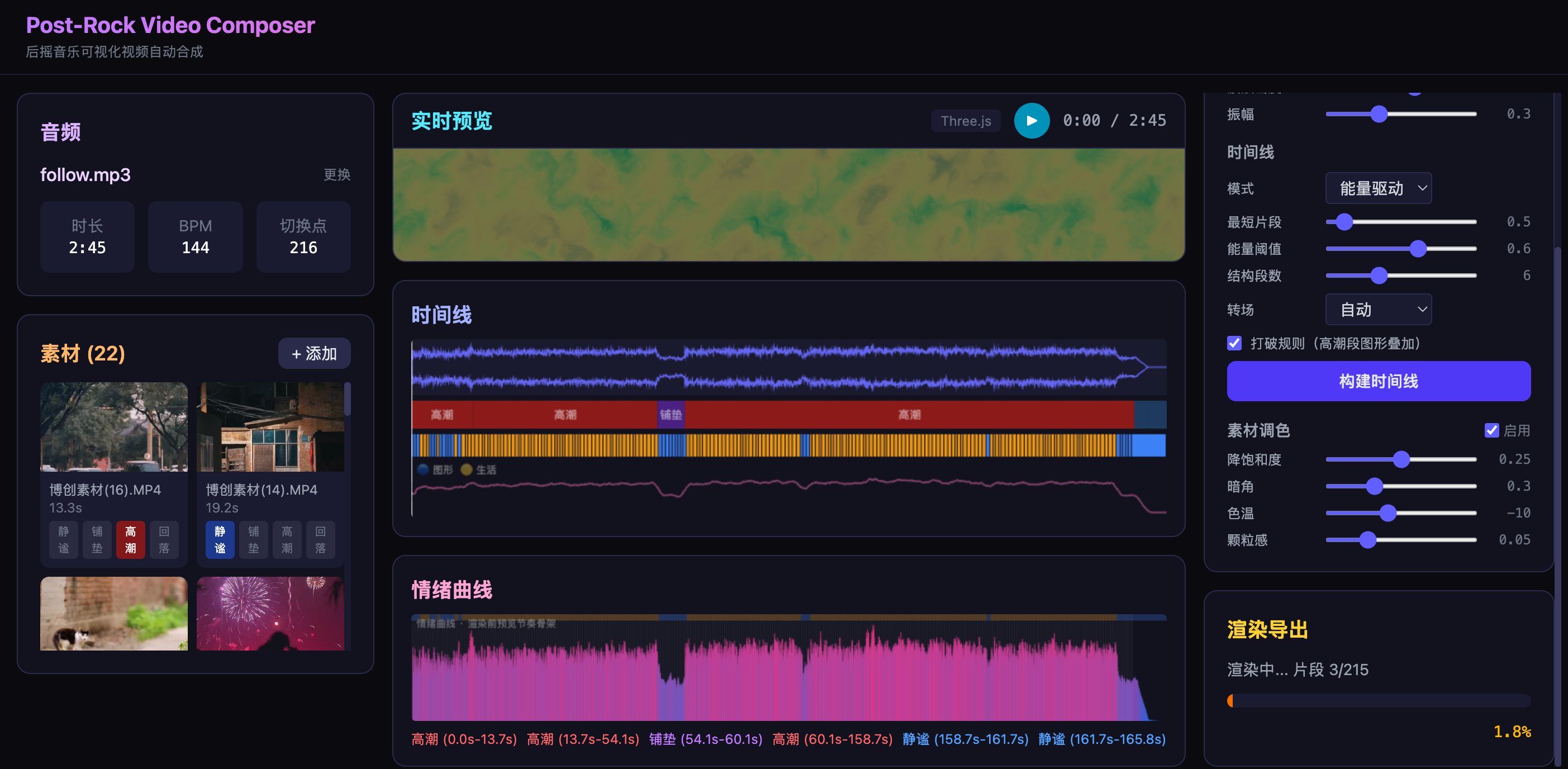
}关键体验:用户上传音乐后,点击播放,右侧画布立即同步显示音频可视化效果。调整左下角的滑块(颜色、波浪密度、振幅系数),画布实时响应。
Step 2.4 - 时间线编辑器
基于 wavesurfer.js 的音频波形 + 自定义段落标注层:
// frontend/src/components/TimelineEditor.tsx
// 核心交互:
// 1. 顶层:wavesurfer.js 渲染音频波形
// 2. 底层:彩色条带标注每个 segment(蓝色=图形段,橙色=生活段)
// 3. 段落边界可拖拽调整
// 4. 点击段落可切换类型(图形 ↔ 生活)
// 5. 播放头同步 p5.js 预览画布Step 2.5 - 参数控制面板
用 shadcn/ui 的 Slider、Select、ColorPicker 组件:
- 视觉风格: 下拉选择 (wave / particle / flow_field)
- 配色方案: 预设调色板选择 (plasma / viridis / cool_warm / custom)
- 波浪密度: 滑块 (50-500)
- 振幅系数: 滑块 (0.1-1.0)
- 最短片段时长: 滑块 (0.3s-2.0s)
- 能量阈值: 滑块 (0.0-1.0)
- 转场类型: 下拉选择 (硬切 / 交叉淡入淡出 / 闪白)
- 素材调色: 开关 (降饱和度 + 暗角)
所有参数通过 Zustand store 管理,变化时实时更新 p5.js 预览。
Step 2.6 - 渲染导出
点击”渲染导出”按钮 → 前端将当前全部参数(时间线 + 视觉配置 + 素材分配)POST 到后端 → 后端异步渲染 → WebSocket 推送进度(百分比 + 当前段落)→ 完成后显示下载链接。
Phase 2.5:6 大增强模块(核心建议全部落地)
以下 6 个模块对应之前提出的 6 条关键建议,每个都有完整的前后端实现。
增强 1:渲染引擎升级路径 (p5.js → Three.js + WebGL Shader)
Phase 1 用 p5.js 的 2D/WebGL 模式快速出效果,Phase 2 升级到 Three.js + 自定义 GLSL shader。
后端不需要改——后端的 OpenCV 渲染器只用于最终导出,和前端预览是独立的。
前端升级路径:
// frontend/src/sketches/shaderSketch.ts (Phase 2)
// 用 Three.js + ShaderMaterial 实现
const fragmentShader = `
uniform float uTime;
uniform float uEnergy;
uniform float uCentroid;
uniform vec2 uResolution;
void main() {
vec2 uv = gl_FragCoord.xy / uResolution;
// 音频驱动的流场
float wave = sin(uv.x * 20.0 + uTime * 2.0) * uEnergy;
wave += sin(uv.y * 15.0 - uTime * 1.5) * uEnergy * 0.5;
// 频谱质心驱动色温
vec3 coldColor = vec3(0.1, 0.2, 0.8);
vec3 warmColor = vec3(0.8, 0.3, 0.1);
vec3 color = mix(coldColor, warmColor, uCentroid);
// 能量驱动辉光
float glow = smoothstep(0.3, 0.0, abs(uv.y - 0.5 + wave * 0.3));
glow *= uEnergy * 2.0;
gl_FragColor = vec4(color * glow, 1.0);
}
`;可实现的效果:
- 粒子爆炸:节拍点触发 1000+ 粒子从中心向外发射,颜色随频谱变化
- 流场:柏林噪声驱动的粒子流动,能量控制流速和密度
- 光晕/辉光:对高亮区域做多次高斯模糊叠加(bloom pass)
- Glitch 效果:高潮段随机 RGB 偏移 + 扫描线,和后摇爆发段的暴力美学匹配
- 几何万花筒:频谱数据驱动多边形旋转和缩放
架构设计:前端 sketches/ 目录下每个文件是一个”视觉预设”,通过 ControlPanel 的下拉菜单切换。新增效果只需添加一个新的 sketch 文件 + 注册到预设列表。
增强 2:三级音频分析体系 + 情绪曲线
DeepSeek 方案只有节拍+onset 两级分析,我们升级为宏观-中观-微观三级:
# backend/services/audio_analyzer.py
class AudioAnalyzer:
def analyze(self, path: str, fps: int = 30) -> AnalysisResult:
y, sr = librosa.load(path)
# ══════ 宏观层:结构分段 ══════
# 检测音乐的大段落边界(intro / build / climax / outro)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
bounds = librosa.segment.agglomerative(mfcc, k=None)
# k=None 让 librosa 自动决定段落数量
structure_times = librosa.frames_to_time(bounds, sr=sr)
# 为每个段落计算平均能量,自动标注情绪
structure_segments = []
for i in range(len(structure_times) - 1):
start, end = structure_times[i], structure_times[i+1]
avg_e = self._avg_rms(y, sr, start, end)
mood = self._classify_mood(avg_e, max_rms)
# mood: "calm" | "building" | "intense" | "release"
structure_segments.append(StructureSegment(
start=start, end=end, mood=mood, avg_energy=avg_e
))
# ══════ 中观层:节拍 + onset ══════
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
onset_frames = librosa.onset.onset_detect(y=y, sr=sr, backtrack=True)
onset_times = librosa.frames_to_time(onset_frames, sr=sr)
cut_points = self._merge_and_filter(beat_times, onset_times, min_gap=0.5)
# ══════ 微观层:逐帧特征 ══════
hop = int(sr / fps)
rms = librosa.feature.rms(y=y, hop_length=hop)[0]
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr, hop_length=hop)[0]
chroma = librosa.feature.chroma_stft(y=y, sr=sr, hop_length=hop)
# ══════ 情绪曲线 ══════
# 连续的情绪值(0-1),用 RMS 平滑后的曲线
mood_curve = self._compute_mood_curve(rms, window_size=fps*2)
return AnalysisResult(
duration=len(y)/sr,
tempo=tempo,
structure_segments=structure_segments,
cut_points=cut_points.tolist(),
rms=rms.tolist(),
spectral_centroid=spec_cent.tolist(),
mood_curve=mood_curve.tolist(),
beat_times=beat_times.tolist(),
onset_times=onset_times.tolist()
)
def _classify_mood(self, avg_energy, max_energy):
"""根据能量比例自动分类段落情绪"""
ratio = avg_energy / max_energy
if ratio < 0.25: return "calm"
elif ratio < 0.50: return "building"
elif ratio < 0.75: return "intense"
else: return "release" # 高能量后通常是释放/回落
def _compute_mood_curve(self, rms, window_size):
"""生成平滑的情绪曲线,用于前端可视化"""
from scipy.ndimage import uniform_filter1d
smoothed = uniform_filter1d(rms, size=window_size)
# 归一化到 0-1
return (smoothed - smoothed.min()) / (smoothed.max() - smoothed.min())前端对接:AnalysisResult 直接传给前端,前端用 EnergyChart 组件绘制情绪曲线,用 TimelineEditor 展示结构分段。
增强 3:素材情绪标签池 + 智能匹配
不再 random.choice 随机选素材,而是按段落情绪自动匹配。
后端:
# backend/services/footage_manager.py
class FootageManager:
MOOD_POOLS = {
"calm": [], # 空街、雨窗、路灯
"building": [], # 早市、行人、交通
"intense": [], # 菜市场特写、烟火、人流
"release": [], # 日落、猫、雨后街景
}
def load_footage(self, dir_path: str):
"""扫描素材目录,按子目录或标签分类到情绪池"""
for video in scan_videos(dir_path):
mood = video.metadata.get("mood", "calm")
self.MOOD_POOLS[mood].append(video)
def get_clip_for_mood(self, mood: str, duration: float) -> Iterator[np.ndarray]:
"""从对应情绪池中随机选取素材,截取指定时长"""
pool = self.MOOD_POOLS.get(mood, self.MOOD_POOLS["calm"])
if not pool:
pool = self._all_clips() # 兜底:没有对应情绪的素材就从全部里选
src = random.choice(pool)
return self._extract_frames(src, duration)前端:素材管理页面每个缩略图下方有 4 个标签按钮(calm / building / intense / release),点击即可分类。未标记的素材默认 calm。
时间线构建时的智能匹配:
# backend/services/timeline_builder.py
def build_timeline(self, analysis, config, footage_mgr):
segments = []
for i, (start, end) in enumerate(pairwise(analysis.cut_points)):
if i % 2 == 0:
seg = Segment(start, end, type="shape")
else:
# 查找当前时间点所属的结构段落
structure_seg = self._find_structure_segment(start, analysis)
mood = structure_seg.mood # calm / building / intense / release
# 从对应情绪池选择素材
footage_id = footage_mgr.select_for_mood(mood, end - start)
seg = Segment(start, end, type="life", mood=mood, footage_id=footage_id)
segments.append(seg)
return Timeline(segments=segments)增强 4:呼吸感转场系统
严格硬切不适合后摇的气质。转场引擎提供多种呼吸感过渡效果。
后端实现:
# backend/core/transitions.py
class TransitionEngine:
def apply_transition(self, prev_frames, next_frames, transition_type, params):
"""在两个片段之间插入转场帧"""
n_transition = params.get("transition_frames", 3) # 转场帧数(默认3帧=0.1秒)
if transition_type == "crossfade":
# 交叉淡入淡出
for i in range(n_transition):
alpha = i / n_transition
blended = (1 - alpha) * prev_frames[-1] + alpha * next_frames[0]
yield blended.astype(np.uint8)
elif transition_type == "ghost":
# 残影叠加:上一段最后一帧以递减透明度叠在下一段开头
ghost_frame = prev_frames[-1]
for i in range(n_transition):
alpha = 0.3 * (1 - i / n_transition) # 从30%透明度递减到0
blended = (1 - alpha) * next_frames[i] + alpha * ghost_frame
yield blended.astype(np.uint8)
elif transition_type == "color_shift":
# 色温渐变:从冷色(图形段)渐变到暖色(生活段)
for i in range(n_transition):
t = i / n_transition
# 冷→暖 或 暖→冷
temperature = lerp(prev_temp, next_temp, t)
frame = self._apply_color_temperature(next_frames[i], temperature)
yield frame
elif transition_type == "flash":
# 闪白:快速白闪(1-2帧),适合高潮段爆发点
yield np.full_like(prev_frames[-1], 255) # 纯白帧
elif transition_type == "blur":
# 模糊过渡:前一段尾帧模糊→清晰→下一段
for i in range(n_transition):
blur_strength = int(20 * (1 - i / n_transition))
if i < n_transition // 2:
frame = cv2.GaussianBlur(prev_frames[-1], (blur_strength*2+1, blur_strength*2+1), 0)
else:
frame = cv2.GaussianBlur(next_frames[0], (blur_strength*2+1, blur_strength*2+1), 0)
yield frame
def select_transition_for_segment(self, prev_seg, next_seg, energy):
"""根据段落类型和能量自动选择转场"""
if energy > 0.8:
return "flash" # 高能量爆发点用闪白
elif prev_seg.type == "shape" and next_seg.type == "life":
return "ghost" # 图形→生活用残影
elif prev_seg.type == "life" and next_seg.type == "shape":
return "color_shift" # 生活→图形用色温渐变
else:
return "crossfade" # 默认交叉淡入淡出“偶尔打破规则”的实现:
# 在时间线构建器中加入"规则打破"逻辑
def _maybe_break_rules(self, segments, analysis):
"""在高能量段落,偶尔让图形叠加在生活素材上,而不是交替"""
for seg in segments:
if seg.type == "life" and seg.avg_energy > 0.85:
seg.overlay_shape = True # 标记:这个生活段要叠加图形层
seg.overlay_alpha = 0.4 # 图形层40%透明度叠加
return segments前端控制面板:
- 转场类型下拉菜单:crossfade / ghost / color_shift / flash / blur / auto
- 转场帧数滑块:1-10 帧(0.03-0.33 秒)
- “自动转场”开关:根据能量自动选择转场类型
- “打破规则”开关:高潮段允许图形叠加在素材上
增强 5:情绪曲线可视化调试面板
在正式渲染前,提供一个全局视图展示整个视频的”节奏骨架”。
前端组件 EnergyChart.tsx:
// frontend/src/components/EnergyChart.tsx
// 用 Canvas 2D 绘制,包含以下层次(从上到下):
// 第1层:能量曲线(平滑后的 RMS,类似山脉轮廓)
// 颜色从蓝(低能量)→ 红(高能量)渐变填充
// 第2层:结构段落标注
// 每个结构段用不同底色:calm=深蓝, building=深紫, intense=深红, release=深绿
// 段落标签文字居中显示
// 第3层:时间段类型标注
// 图形段(S)和生活段(L)交替的彩色窄条
// S=蓝色, L=橙色
// 第4层:选用素材预览
// 每个生活段下方显示对应素材的缩略图小图标
// 交互:
// - 鼠标悬停显示具体时间点的能量值、段落类型、素材名
// - 点击定位到该时间点,p5.js 预览跳转
// - 播放时有一条竖线随时间移动视觉效果示意(ASCII):
能量: ▁▁▂▃▅▇█████▇▅▃▂▁▁▁▂▃▅▇████████▇▅▂▁
段落: [ calm ][ building ][ intense ][release]
类型: S L S L S L S L L L L S L L L S L S L S S
素材: 空街 -- 市场 -- 行人 快切快切快切 夜灯 猫
转场: .. cf .. gh .. cf fl fl fl cs .. cf .. ghcf=crossfade, gh=ghost, fl=flash, cs=color_shift
这个面板让用户在渲染前就能看到整个视频的节奏骨架,确认:
- 段落分配是否合理(安静段是不是真的放了安静素材?)
- 切换频率是否舒服(有没有某段切得太密?)
- 转场选择是否得当(爆发点是不是用了闪白?)
增强 6:生活素材统一调色系统
原始拍摄素材色调五花八门,和动态图形放在一起会很”割裂”。调色系统在素材上传时自动处理。
后端实现:
# backend/services/color_grader.py
class ColorGrader:
def __init__(self, config: ColorGradeConfig):
self.desaturation = config.desaturation # 降饱和度比例 (0-1, 默认0.25)
self.vignette_strength = config.vignette # 暗角强度 (0-1, 默认0.3)
self.temperature_shift = config.temperature # 色温偏移 (-50到+50, 默认-10偏冷)
self.grain_strength = config.grain # 颗粒感强度 (0-1, 默认0.05)
def grade_frame(self, frame: np.ndarray) -> np.ndarray:
result = frame.copy()
# 1. 降饱和度(让画面更接近"电影感")
hsv = cv2.cvtColor(result, cv2.COLOR_BGR2HSV).astype(np.float32)
hsv[:, :, 1] *= (1 - self.desaturation)
result = cv2.cvtColor(hsv.astype(np.uint8), cv2.COLOR_HSV2BGR)
# 2. 暗角(四角压暗,聚焦中心)
h, w = result.shape[:2]
Y, X = np.ogrid[:h, :w]
center_y, center_x = h / 2, w / 2
dist = np.sqrt((X - center_x)**2 + (Y - center_y)**2)
max_dist = np.sqrt(center_x**2 + center_y**2)
vignette = 1 - self.vignette_strength * (dist / max_dist) ** 2
result = (result * vignette[:, :, np.newaxis]).astype(np.uint8)
# 3. 色温偏移(统一冷暖调)
if self.temperature_shift != 0:
result = self._shift_temperature(result, self.temperature_shift)
# 4. 颗粒感(film grain,增加质感)
if self.grain_strength > 0:
noise = np.random.normal(0, self.grain_strength * 25, result.shape)
result = np.clip(result.astype(np.float32) + noise, 0, 255).astype(np.uint8)
return result
def _shift_temperature(self, frame, shift):
"""正值偏暖(加红减蓝),负值偏冷(加蓝减红)"""
result = frame.astype(np.float32)
result[:, :, 2] = np.clip(result[:, :, 2] + shift, 0, 255) # R
result[:, :, 0] = np.clip(result[:, :, 0] - shift, 0, 255) # B
return result.astype(np.uint8)应用时机:
- 素材上传时:后端自动生成”调色后”版本,保存为预处理文件
- 渲染时:读取预处理后的素材帧
- 前端预览:不需要调色(预览重点是看节奏和布局,不是色彩)
前端控制面板:
- “统一调色”总开关
- 降饱和度滑块:0-50%
- 暗角强度滑块:0-100%
- 色温偏移滑块:-50(冷)到 +50(暖)
- 颗粒感强度滑块:0-100%
- 调色预览:在素材管理页面,鼠标悬停显示调色前/后对比
Phase 3:进阶功能(可选扩展)
- 预设模板系统:保存/加载整套参数配置(”后摇史诗风”、”lo-fi 安静风”、”glitch 赛博风”等)
- 多进程渲染:
multiprocessing.Pool并行生成帧,4 核 CPU 提速 3-4 倍 - Playwright 导出模式:用无头浏览器运行前端 p5.js/Three.js 代码导出帧,实现预览和最终渲染像素级一致
- AI 辅助素材标签:接入 CLIP 模型自动给素材打情绪标签
- 音频结构手动覆盖:在时间线编辑器中手动划分 intro/build/climax/outro,覆盖 librosa 自动检测
- 歌词/文字叠加:支持在特定时间点叠加文字,字体和透明度随能量变化
性能预估
- 音频分析:5 分钟音频 librosa 三级分析 ~5-10 秒
- 时间线构建:瞬时 (<100ms)
- 前端预览:实时 60fps(p5.js WebGL 模式)
- 后端渲染(OpenCV + FFmpeg):
- 1080p 30fps 5 分钟 → 约 3-5 分钟
- 720p 30fps 预览模式 → 约 1-2 分钟
- FFmpeg 音频合成:~10 秒
风险与应对
- 后摇节拍检测不准:librosa 结构分段 + onset 双重保险;前端时间线编辑器支持手动修正
- p5.js 预览与后端渲染效果不一致:两者使用相同的数学公式和参数,允许轻微差异(预览是创意方向参考,不是像素级 WYSIWYG)
- 大文件上传慢:使用分块上传 + 进度条;素材文件建议预处理为 720p 减小体积
- 渲染时间长:WebSocket 进度推送 + 支持取消;后续可用多进程并行渲染帧
- 素材数量不足:支持单条素材循环/慢放;在 UI 中提示”建议至少 5 条不同素材”