搭了一套全自动"聊天记录短视频"生产线
搭建了一套全自动”聊天记录短视频”生产线
从截图到原创视频,全链路自动化,日产 3 条,零人工干预。
起因:一个被平台判”非原创”的号主
做过微信视频号的人大概都踩过这个坑:直接搬运别人的聊天截图做视频,平台一识别就判定”非原创”——限流、扣分、甚至封号。
我的号也遇到了这个问题。素材来源是网上收集的搞笑聊天截图,虽然内容很火,但平台的图片指纹算法太强了,哪怕你加个滤镜、换个边框,该识别还是能识别。
问题的本质很清楚:你用的还是别人的图。
所以我想到了一个思路:把截图里的文字提取出来,用程序重新画一张全新的聊天界面图。像素级别完全不同,但内容等价。这不就是”原创”了吗?
于是有了这个项目:ChatVideo — 聊天记录视频生成系统。
整体架构:六步流水线
整个系统的工作流可以用一句话概括:
打标 → 拼图 → AI 识别 → Canvas 渲染 → FFmpeg 合成 → 自动发布展开来说:
- 打标(Labeling):从数据库素材池里挑出”有聊天记录的截图”,人工标记是/否
- 拼图 + AI 识别(Vision Extract):随机取 N 张已标记图片拼成大图,调用 AI 视觉模型一次性识别出所有对话内容,输出结构化的 Chat DSL(JSON)
- Canvas 程序化渲染(Rendering):用
@napi-rs/canvas把 JSON 逐像素画成微信聊天界面,包括状态栏、头部导航、气泡、头像、输入栏,像素级还原 - FFmpeg 视频合成(Composing):9 张图 + AI 生成的背景音乐 + 毛玻璃背景效果 + 滑动水印,合成 1080x1920 竖屏视频
- AI 生成元数据:标题、描述、话题标签,全部由 AI 生成
- 自动发布(Publishing):Python + Playwright 自动登录微信视频号后台,上传视频
技术栈:Node.js + Express + EJS + MySQL + @napi-rs/canvas + FFmpeg + MMX CLI + DeepSeek API + Python Playwright
代码量:核心源码约 6000 行(不含 node_modules 和第三方依赖)。
核心难点一:像素级还原微信聊天界面
这是整个项目最有技术含量的部分。chat-renderer.js 单文件 927 行,几乎就是一个 Canvas 2D 绘图引擎。
为什么不用 HTML + Puppeteer 截图?
试过。两个问题:
- 慢。Puppeteer 启动浏览器 + 渲染 + 截图,单张图片需要 2-3 秒,9 张就是 20 多秒
- 不够精确。浏览器的 CSS 渲染和真实微信界面总有微妙差异,尤其是字体渲染、行高、气泡圆角
最终选择了 @napi-rs/canvas(Rust 实现的 Node.js Canvas 绑定),性能极好,单张图渲染 100-300ms。
渲染的完整要素
一张完整的微信聊天截图需要渲染这些元素:
┌────────────────────────────┐
│ 状态栏(时间、信号、WiFi、电池) │ ← drawStatusBar()
├────────────────────────────┤
│ 导航栏(返回箭头 + 联系人名) │ ← drawHeader()
├────────────────────────────┤
│ │
│ 聊天区域 │
│ ├ 时间标记(居中灰色) │ ← drawTimeLine()
│ ├ 左侧气泡(白色 + 三角箭头) │ ← drawTextBubble()
│ ├ 右侧气泡(绿色 + 三角箭头) │ ← drawTextBubble()
│ ├ 语音消息(波形条 + 时长) │ ← drawVoiceBubble()
│ ├ 红包消息(橙色卡片) │ ← drawRedpacketBubble()
│ └ 转账消息(橙色卡片 + 金额) │ ← drawTransferBubble()
│ │
├────────────────────────────┤
│ 输入栏(语音/输入框/表情/更多) │ ← drawInputBar()
├────────────────────────────┤
│ 底部安全区 + Home Indicator │ ← drawHomeIndicator()
└────────────────────────────┘主题系统
所有 UI 参数都不是硬编码的,而是通过 JSON 主题文件配置:
{
"name": "wechat-green",
"canvas": { "width": 1080, "height": 1920 },
"chat": {
"bubble": {
"left": { "bgColor": "#FFFFFF", "font": "400 46px ChatFont", "radius": 14 },
"right": { "bgColor": "#95EC69", "font": "400 46px ChatFont", "radius": 14 }
}
}
}换一套 JSON,就能输出完全不同风格的界面(深色模式、iMessage 蓝、温暖粉等)。系统支持主题轮换策略,每个视频自动切换风格,进一步提升”原创度”。
动态画布高度
早期版本画布高度固定为 1920px,消息太多时底部会被截断。后来改成了动态画布:先在一个”无限高”的虚拟画布上渲染所有消息,计算实际需要的高度,再裁剪到最终尺寸。
// 先用超大画布渲染,计算实际高度
const tempCanvas = createCanvas(W, Math.max(H, 4000));
// ... 渲染所有消息 ...
const actualH = Math.max(H, cursorY + 200);
// 再画到正式画布
const finalCanvas = createCanvas(W, H);
const finalCtx = finalCanvas.getContext('2d');
finalCtx.drawImage(tempCanvas, 0, 0);Emoji 渲染
这个坑踩了很久。@napi-rs/canvas 默认不支持彩色 Emoji 渲染(显示为方块)。解决方案是分段渲染:
- 把文本按 Emoji 正则分段
- 普通文字用
fillText绘制 - Emoji 用系统的 Apple Color Emoji 字体预渲染到临时 canvas,再
drawImage合成
还踩了一个 JavaScript 正则的经典坑:全局正则的 lastIndex 状态不重置,导致连续调用结果交替正确/错误。
核心难点二:AI 对话提取与生成
Chat DSL:对话的结构化描述
我设计了一套 Chat DSL(Domain Specific Language) 来描述聊天内容:
{
"contactName": "宝贝",
"participants": [
{ "id": "A", "side": "right", "gender": "female" },
{ "id": "B", "side": "left", "gender": "male" }
],
"messages": [
{ "type": "time", "content": "下午 3:42" },
{ "from": "A", "type": "text", "content": "你在干嘛" },
{ "from": "B", "type": "text", "content": "想你" },
{ "from": "A", "type": "voice", "content": "", "params": { "duration": 3 } },
{ "from": "B", "type": "redpacket", "content": "", "params": { "remark": "买奶茶" } },
{ "from": "A", "type": "transfer", "content": "", "params": { "amount": "520.00", "remark": "爱你" } }
],
"summary": "情侣间甜蜜的日常互动"
}支持 5 种消息类型:text(文本)、time(时间/系统消息)、voice(语音)、redpacket(红包)、transfer(转账)。有 dsl/schema.js 做验证和规范化。
两条内容生产线
线路一:视觉提取(Vision Extract)
已标记截图 → 拼成大图 → MMX Vision API 识别 → 输出 Chat DSL JSON这条线路的核心是 Prompt 工程。提取时需要精确识别:
- 谁说的话(左/右侧)
- 消息类型(文本/语音/红包/转账/系统消息)
- 系统消息 vs 普通消息的区分(居中灰色小字 vs 气泡消息)
- 参与者的性别推断
提取出来的文字会做极小幅度的改写以规避查重,但有严格的”禁改区”——谐音梗、双关语、上下文呼应词绝对不能改。这个规则是被用户投诉后才加上的:比如”我的卷发棒在哪里” → “棒就棒在好看”,AI 把”卷发棒”改成了”卷发器”,整个梗就没了。
线路二:LLM 凭空生成
精心设计的 Prompt → LLM 直接生成 Chat DSL JSONPrompt 里定义了多种内容风格:
- 反转型:前面正常聊天,最后一句画风突变
- 搞笑型:抖机灵、谐音梗、离谱误会
- 扎心型:看着搞笑其实戳心窝子
- 社死型:发错消息、截图发错人
还有十几个主题随机混搭:情侣日常、闺蜜八卦、相亲翻车、借钱名场面……
AI 调优:DeepSeek / MMX 双引擎
OCR 提取的对话经常有问题——错别字、A/B 角色颠倒、语义不通。于是做了一个”调优”功能:
点击”调优”按钮 → 调用 DeepSeek API(或 MMX,通过 .env 切换)→ 自动检查 4 类问题:
- OCR 错别字:形近字误识别(”已”→”己”)
- 角色分配错误:对话逻辑不通,A 和 B 该互换
- 语义不通顺:漏字、多字
- 结构问题:time 消息不该有 from 字段
检测结果以可视化的方式展示(原文删除线 → 修正后绿色高亮),确认后一键保存。
LLM 输出的 JSON 修复
和 LLM 打交道最头疼的就是:它返回的 JSON 经常是坏的。
常见问题:尾随逗号、多余的 markdown 代码块标记、控制字符、括号不匹配。为此写了一个 repairJson 函数,能处理 90% 以上的畸形 JSON:
function repairJson(text) {
let s = text.trim();
s = s.replace(/```json\s*/g, '').replace(/```\s*/g, '');
s = s.replace(/,\s*([}\]])/g, '$1'); // 尾随逗号
s = s.replace(/[\x00-\x1F\x7F]/g, ' '); // 控制字符
// ... 更多修复规则 ...
// 括号平衡检查
let opens = (s.match(/\[/g) || []).length;
let closes = (s.match(/\]/g) || []).length;
while (closes < opens) { s += ']'; closes++; }
return s;
}配合重试机制,整体成功率能到 95%+。
核心难点三:视频合成
毛玻璃背景效果
渲染出的聊天图片是竖屏的(1080x1920),但有些图片高度不够 1920px。直接黑边填充太丑了。
最终方案是毛玻璃效果:把原图放大模糊作为背景,再把清晰的原图叠在正中间。FFmpeg 的滤镜链:
[0:v]scale=1080:1920:force_original_aspect_ratio=increase,crop=1080:1920,boxblur=30:10[bg]
[0:v]scale=1080:1920:force_original_aspect_ratio=decrease[fg]
[bg][fg]overlay=(W-w)/2:(H-h)/2[out]效果类似 iOS 的毛玻璃,既填满了画面又不突兀。
滑动水印
为了防盗和品牌露出,加了一个在视频中缓慢漂移的半透明水印”@测试水印”。
技巧在于用 sin/cos 函数控制运动轨迹,并且每次合成都随机化相位和速度:
const sx = (baseSx * (0.7 + Math.random() * 0.6)).toFixed(4); // 速度随机
const phaseX = (Math.random() * Math.PI * 2).toFixed(4); // 相位随机
// FFmpeg drawtext 表达式
x = '100+(W-tw-200)*(0.5+0.5*sin(t*${sx}+${phaseX}))'
y = '200+(H-th-400)*(0.5+0.5*cos(t*${sy}+${phaseY}))'这样每个视频的水印轨迹都不同——起始位置不同、运动形状不同(有的偏椭圆,有的偏圆),避免了”所有视频水印走一样的路”。
水印文字和速度都通过 .env 配置,想关闭把 WATERMARK_TEXT 留空即可。
合成流程
完整的视频合成是一个 7 步流水线:
1. 查询可用 Chat DSL(随机取 9 条)
2. 逐张 Canvas 渲染为 PNG
3. AI 生成视频元数据(标题、描述、话题)
4. AI 生成背景音乐
5. FFmpeg 逐张合成片段(毛玻璃背景,每张 3 秒)
6. 拼接片段 + 混合音轨 + 添加滑动水印
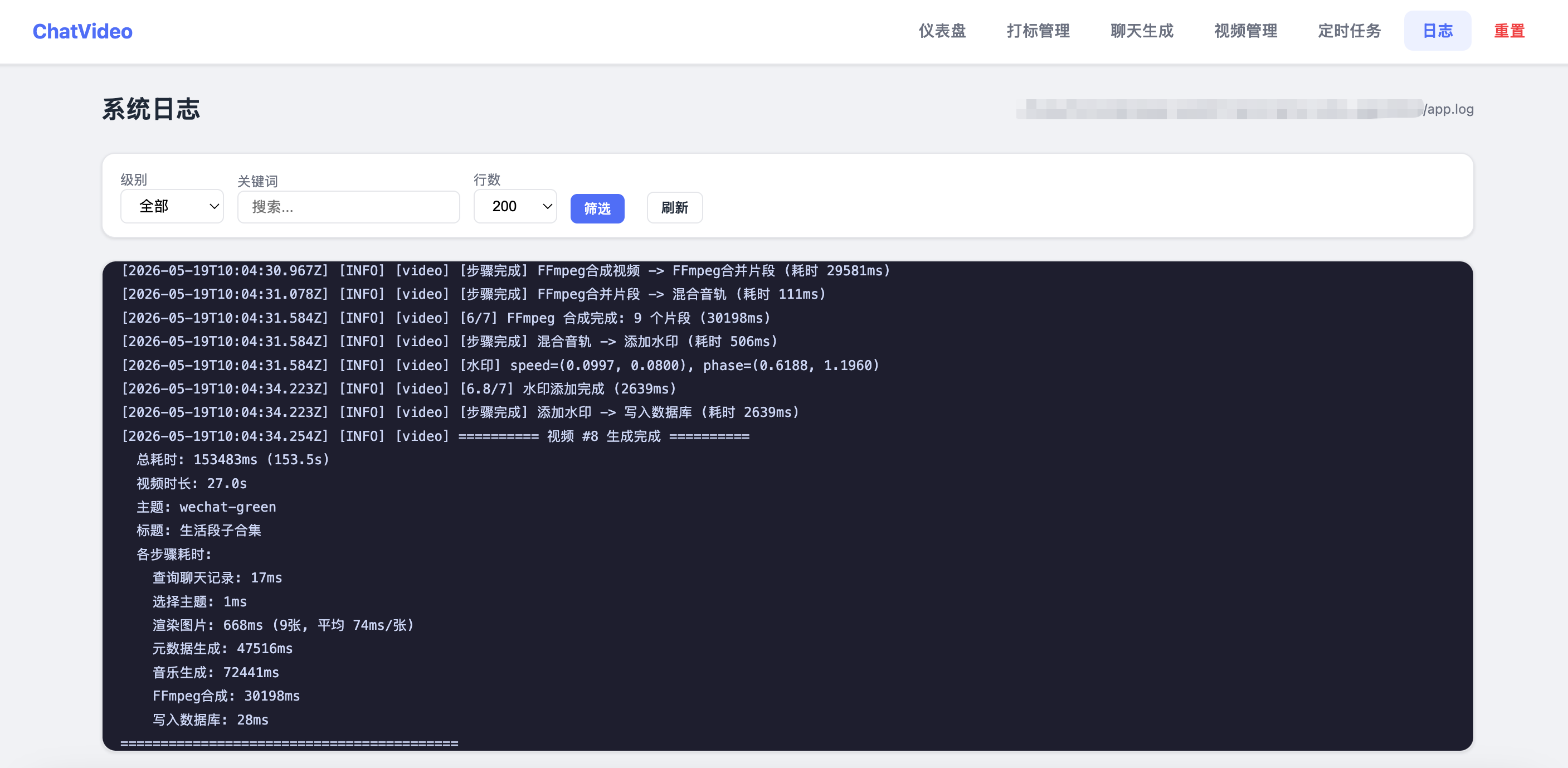
7. 写入数据库每一步都有详细的耗时日志和进度回调,前端可以实时看到当前执行到哪一步。
管理后台
Web 管理界面
用 Express + EJS 做了一个完整的管理后台,包括:
| 模块 | 路径 | 功能 |
|---|---|---|
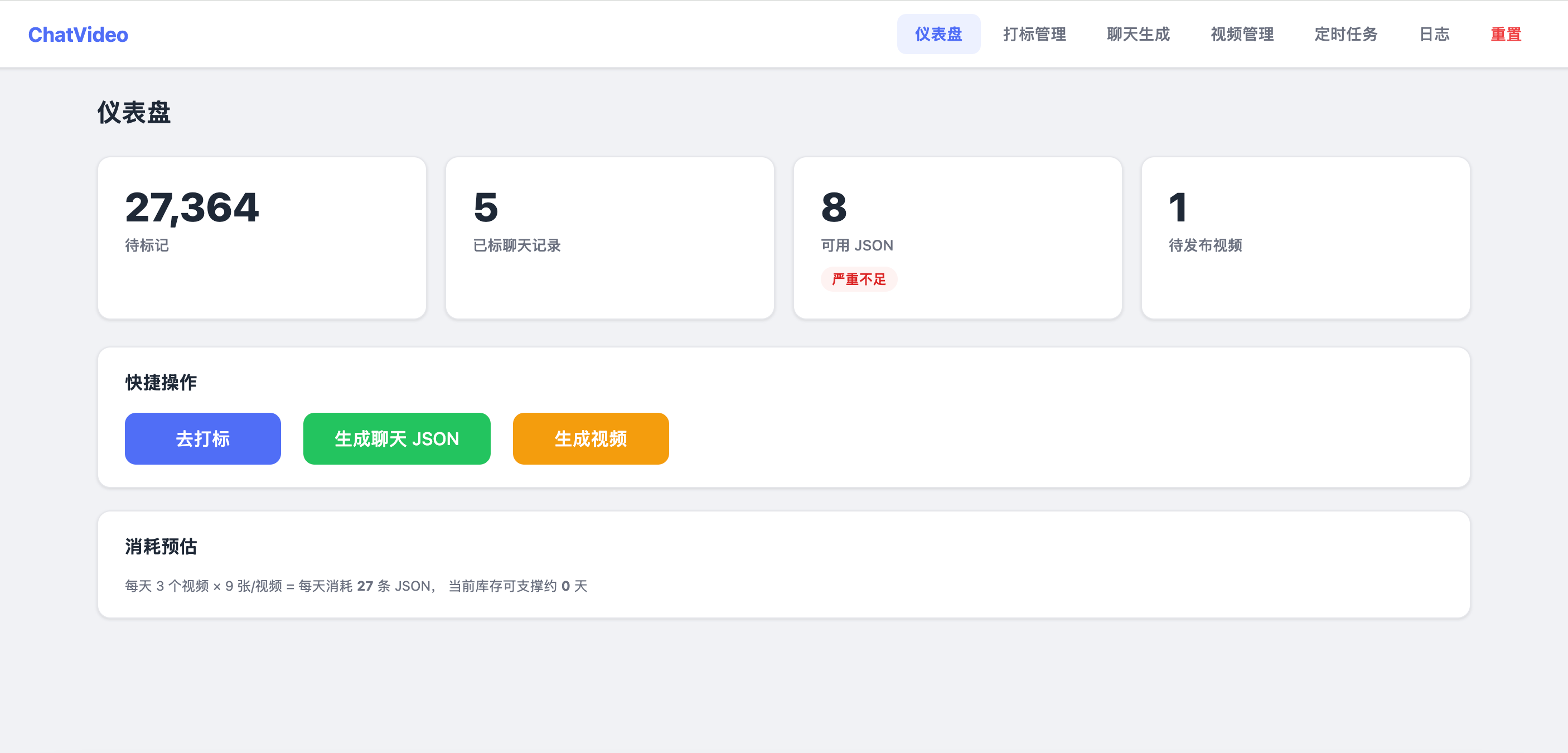
| 仪表盘 | / |
数据总览:待标数、已标数、可用 JSON、已生成视频 |
| 打标管理 | /labeling |
3x3 卡片布局,是/否快速标记,悬浮大图预览 |
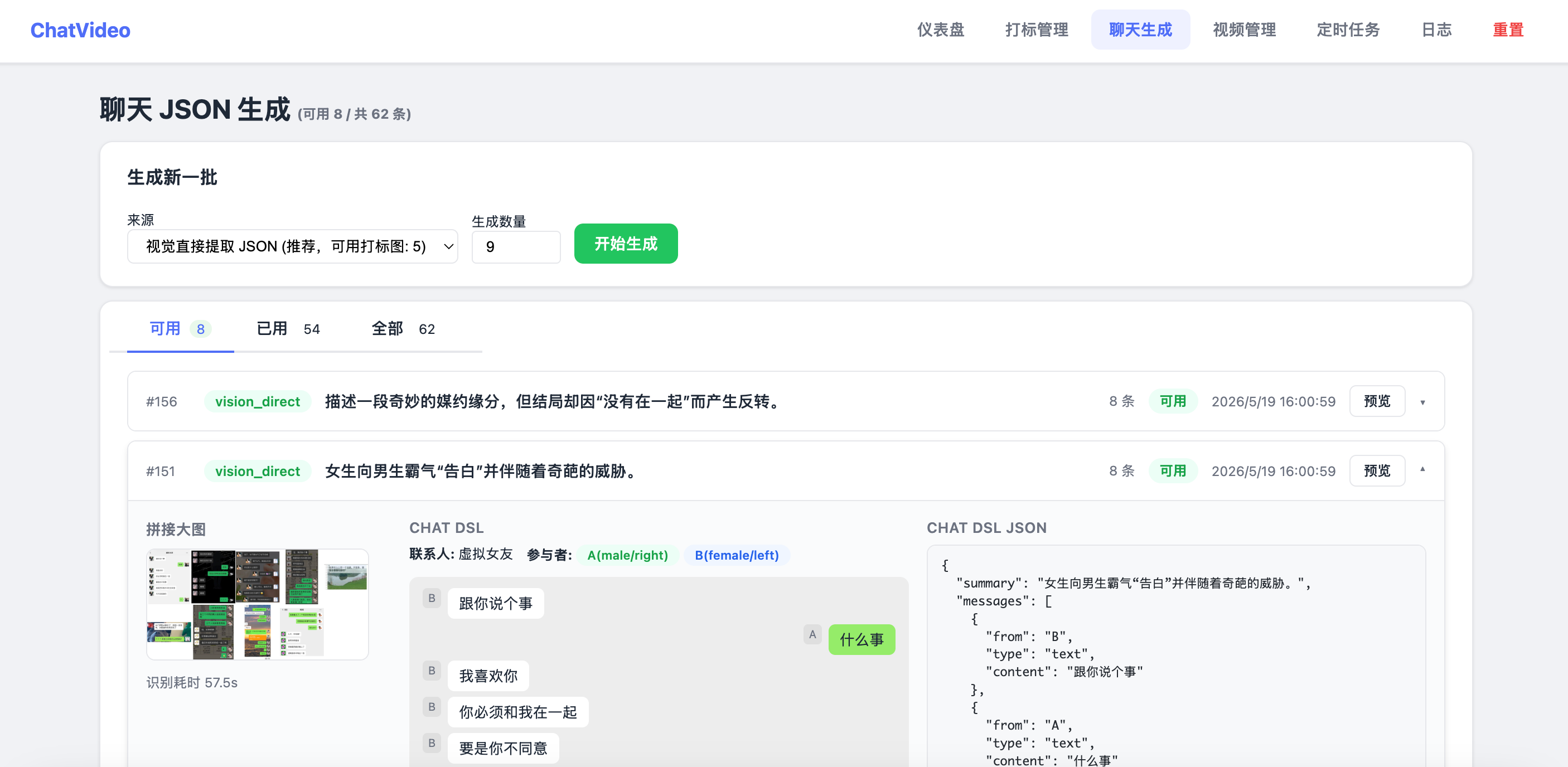
| 聊天 JSON 生成 | /generation |
生成、预览、编辑 DSL、AI 调优,分页+Tab 筛选 |
| 视觉任务 | /generation/vision |
拼接大图预览,关联的聊天记录 |
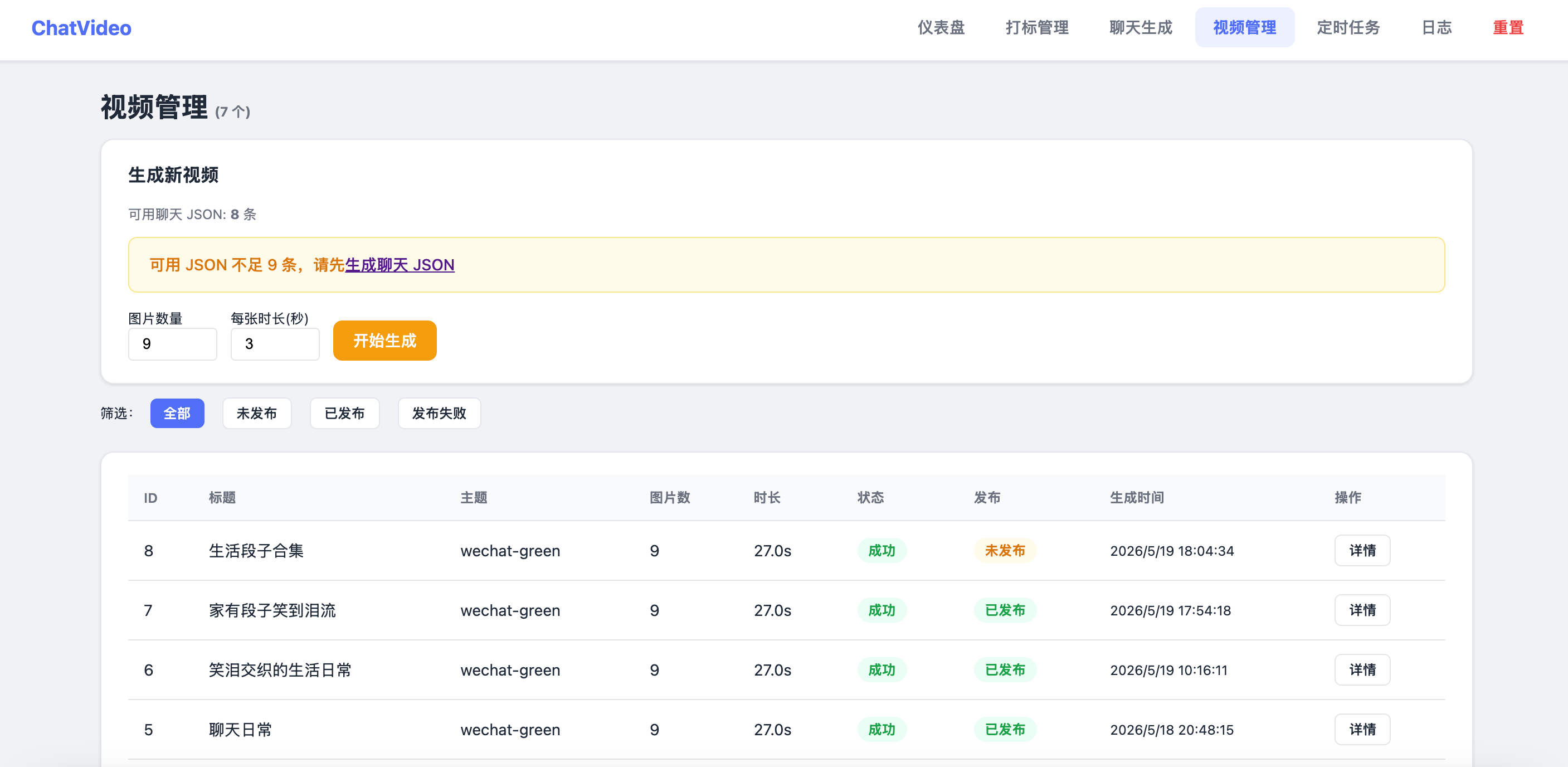
| 视频管理 | /videos |
视频列表、生成表单、播放预览 |
| 定时任务 | /system/cron |
查看/手动触发定时任务 |
| 系统重置 | /system/reset |
重置已用标签、已用 JSON 等 |
| 日志查看 | /system/logs |
实时查看系统日志 |
全站响应式设计,手机也能操作。
定时任务
系统启动后自动运行两个 Cron 任务:
- 每 4 小时:检查可用 JSON 数量,不足 50 条时自动补充
- 每天 8:30 / 12:30 / 18:30:检查待发布视频数量,不足 5 个时自动合成
API 接口
GET /api/stats → 各池数量统计
GET /api/preview/:id → 即时渲染某条 Chat DSL 为 PNG
GET /api/video/next → 获取下一个待发布视频(Bearer Token 鉴权)
POST /api/video/publish → 回调:更新发布状态发布脚本通过这些 API 和主系统交互,实现松耦合。
自动发布:Python + Playwright
publisher/ 目录是一个独立的 Python 项目,用 Playwright 自动化操作微信视频号后台:
- 首次运行手动登录,保存 Cookie
- 后续运行自动加载 Cookie
- 调用 API 获取待发布视频
- 自动上传视频文件
- 填写标题、描述、话题标签
- 提交发布
- 回调 API 更新状态
整个发布流程全自动,只有 Cookie 过期时需要人工介入重新登录。
踩过的坑(精选)
1. SQL 别名不匹配
SELECT COUNT(*) AS cnt FROM generated_chats WHERE is_used = 0JavaScript 里却 const { available } = rows[0]。这种 bug 不报错,只是默默返回 undefined,页面上显示为空。后来统一了命名规范。
2. 任务锁未释放
生成任务失败后,runningTask 被设为 { status: 'failed', ... } 而不是 null,导致后续请求被误判为”已有任务在运行中”。修复:判断条件从 if (runningTask) 改为 if (runningTask?.status === 'running')。
3. 视频时长不对
9 张图 x 3 秒 = 27 秒,但实际合成出来 40 秒。原因:之前根据每张图的消息数量动态计算展示时长(消息越多展示越久),改成固定 3 秒后问题解决。
4. 系统消息误识别
AI 经常把普通聊天消息识别为系统消息(居中灰色小字)。加了后处理函数,用正则白名单过滤:只有包含”撤回””新消息””拍了拍””已添加”等关键词的才算系统消息,其余强制改回普通文本。
5. 谐音梗被 AI 改坏了
最经典的案例:”我的卷发棒在哪里” → “棒就棒在好看”。AI 把”卷发棒”改成了”卷发器”,整个梗没了。被用户投诉后,在 Prompt 里加了严格的”禁改区”规则:谐音梗的关键词、上下文呼应词、构成笑点的核心词汇,一个字都不能动。
项目结构
original-video-agent/
├── src/
│ ├── app.js # Express 入口
│ ├── config.js # 环境配置(.env 读取)
│ ├── db.js # MySQL 连接池
│ ├── dsl/schema.js # Chat DSL 验证与规范化
│ ├── routes/
│ │ ├── home.js # 仪表盘
│ │ ├── labeling.js # 打标管理
│ │ ├── generation.js # 聊天 JSON 生成 + 调优
│ │ ├── video.js # 视频管理
│ │ ├── api.js # REST API
│ │ └── system.js # 系统管理(cron/reset/logs)
│ ├── services/
│ │ ├── chat-generator.js # AI 对话提取与生成 (548 行)
│ │ ├── chat-renderer.js # Canvas 像素级渲染 (927 行)
│ │ ├── video-composer.js # FFmpeg 视频合成 (358 行)
│ │ ├── tuner.js # AI 调优(DeepSeek/MMX 双引擎)
│ │ ├── mmx.js # MMX CLI 封装
│ │ ├── theme-loader.js # 主题加载与轮换
│ │ ├── cron.js # 定时任务
│ │ └── logger.js # 统一日志
│ ├── themes/
│ │ └── wechat-green.json # 微信经典绿主题
│ ├── assets/
│ │ ├── avatars/ # 头像库(male/female/unknown)
│ │ ├── fonts/ # NotoSansSC 中文字体
│ │ └── ui/ # UI 元素素材
│ ├── views/ # 12 个 EJS 页面模板
│ └── public/ # CSS + JS 静态资源
├── publisher/ # Python 自动发布脚本
├── migrations/ # 数据库迁移
├── data/ # 运行时数据(视频/音乐/拼接图)
└── .env # 环境配置数据库设计
三张核心表:
vo_dynamic(素材表,已有)
label_state:0=待标, 1=聊天记录, 2=非聊天, 3=已使用
generated_chats(聊天 JSON)
chat_dsl:完整的 Chat DSL JSONsummary:一句话摘要source:来源(vision_direct / llm)is_used:是否已用于合成视频vision_task_id:关联的视觉识别任务
videos(视频记录)
title、description、short_title、topicsvideo_path、music_pathchat_ids:使用的 JSON ID 列表status:draft / published
vision_tasks(视觉识别任务)
stitched_image_path:拼接大图路径chat_count:识别出的对话数量duration_ms:识别耗时
效果与收益
上线后的数据:
- 日产能:3 条视频 / 天(定时任务自动合成)
- 单视频合成时间:约 2 分钟(9 张图渲染 + 音乐生成 + FFmpeg 合成)
- 原创度:100% 通过微信视频号原创检测
- 人工介入:仅打标环节需要人工(约 10 分钟 / 批),其余全自动
技术选型的思考
| 决策 | 选择 | 原因 |
|---|---|---|
| 图片渲染 | @napi-rs/canvas | 性能是 Puppeteer 的 10 倍,像素级控制 |
| 后端框架 | Express + EJS | 简单够用,SSR 不需要前端构建工具 |
| 视频合成 | FFmpeg | 工业标准,滤镜链足够强大 |
| AI 接口 | MMX CLI + DeepSeek API | 双引擎互备,按需切换 |
| 数据库 | MySQL | 项目已有基础设施 |
| 发布自动化 | Playwright | 对微信后台的模拟操作最稳定 |
| 模板语言 | EJS | 无需前端构建,服务端渲染即可 |
没有用 React/Vue/Next.js,因为这是一个内部工具,SSR + 原生 JS 足够。过度工程化只会增加维护成本。
总结
这个项目的核心思路其实很简单:把”搬运”变成”再创作”。
别人的聊天截图是一张图片,我把它变成结构化的数据(Chat DSL),再用程序重新渲染成一张全新的图片。从平台的角度看,这是一张从未出现过的图片——因为它确实是程序画出来的。
但要让这个思路真正跑起来,涉及的工程细节远超预期:字体渲染、Emoji 兼容、气泡箭头绘制、动态画布高度、LLM 输出修复、系统消息识别、视频背景处理、水印随机化……每一个点都是一个坑。
如果你也在做类似的短视频自动化,希望这篇文章能给你一些启发。