打标系统
事情的起因是这样,之前一直刷微信视频号,看到有人发那种搞笑的微信对话记录,于是我自己写了一个爬虫,找了一批搞笑的图片,但是里面除了搞笑的对话记录图片,还有各种其他的搞笑图片,我需要把他们择出来,然后找到背景音乐、使用ffmpeg合成一段视频。
以下是一段持续迭代升级的过程,并且后续还可能会继续升级。当然这取决于ai技术的发展和消耗token的花费,总之要算一下ROI吧…
很早之前的第一版
写了一个web页面,自己人工筛选,把所有对话记录筛选出来,一屏9张图批量打标;费眼睛费手;再从素材网站上找一些高效的背景音乐素材;然后将打标好的图片+音乐,使用程序合成视频,人工发布到视频号;根据爬虫拿到的对图片的描述自己再改写视频描述、标签、短标题,纯纯体力活。
纯人工打标,使用的自己的大脑🧠,不消耗token,只消耗两个馒头!
大幅提效的第二版
我们是搞技术的,怎么可能只消耗馒头不消耗算力呢?这一版主要更新了什么?
- 打标:打标还是纯纯人工打标,一页9张图,这次我把服务放到了阿里云的机器上,适配了手机端,躺着床上也可以打标。
- 背景音乐:那会
minimax发布了M2.7,我买了token plan,可以通过自然语言生成欢快轻松的背景音乐(纯音乐),也可以使用歌词唱出来,但是我不需要; - 合成视频:合成视频还是使用
ffmpeg,视频描述、标签、短标题 这三项也使用 mmx 来自动生成,还是根据爬虫拿到的图片描述; - 发布脚本:之前在
github上找了很久,没找到合适的自动发布的脚本或者工具;然后自己使用opus4.6写了一个,放在自己本地;发布流程相当于是 本地启动脚本,从服务器拉视频拉描述标签短标题(我特意写了一个api接口),然后本地手机扫码登录,自动化发布;这个cookie有效期很短,过一会儿就得重新扫码,也还行。
本以为这样就完美了,结果突然有一天,平台发来一条私信,说我的短视频非原创,我当时就tm想,确实,我这个的确是非原创…
但是我音乐是原创,排序是原创,视频描述、标签、短标题都是原创,AI创也是原创。我申诉了,结果可想而知…
于是我痛定思痛,再搞第三版,AI 已经发展到如此地步,我一定要让 AI 帮我想一个什么方案,能彻底不需要人工。
盗版可耻…
过渡的第三版
为什么平台会判定我为非原创,我认为最根本的原因就是平台的OCR,识别出来我的内容和其他用户的内容完全一致,因为我的图片就是盗版的图片,和人家的完全一模一样,不仅仅是文字,背景图、头像,系统消息(时间、撤回、拒收等等)都一样。所以我需要做的就是:
提取文字 --> AI润色 --> 填回原图(填回是不可能了,只能用程序重新绘制一张图吧)第三版其实也是一个过渡版本,没有使用只是技术实验,最终被否定了。
这一版使用的是 minimax 的视觉模型,最初为了省钱,我把9张图片拼到一起,拼成一张9宫格的大图,然后让模型一次性识别9组json格式的对话记录,格式如下:
{"summary":"兄弟会错意,把女友叫来了","messages":[{"from":"A","type":"text","content":"哥们,心情不太好"},{"from":"A","type":"text","content":"跟你女朋友说一声,晚上陪我喝点去咋样"},{"from":"B","type":"text","content":"好,我和她说一下"},{"from":"A","type":"text","content":"想吃啥?我来点"},{"from":"B","type":"text","content":"你们俩商量吧,我已经让她过去了"},{"from":"A","type":"text","content":"?????"},{"from":"A","type":"text","content":"我是让你过来,只是跟她说一声"}],"contactName":"大林","participants":[{"id":"A","name":"我","side":"right","gender":"male"},{"id":"B","name":"大林","side":"left","gender":"male"}]}这里面就有两个问题:
- 虽然一次识别9组对话记录,9次调用合为1次调用,是省钱,但是增加了视觉模型的难度,本来视觉模型就不聪明,我还给她上难度,导致识别出来的内容,基本上不太行,我把这个视频发出去还用户被骂了…haha😁
- 视觉模型只识别出来了文字,但是很多对话记录元素复杂,有表情、图片、转账、红包、语音、系统消息(撤回、拍一拍、拒收等等),这些根本识别不出来,导致我程序绘制的结果更加的不行,啥都没有
然后我就找 AI 帮忙,有没有什么方案能够解决这一问题。
基本可行的第四版
https://docs.ultralytics.com/zh/models/yolov8
AI推荐我使用👆🏻这个目标检测模型,在本地训练一下来完成这个任务,然后我按步骤搭建了这个模型以及打标平台:
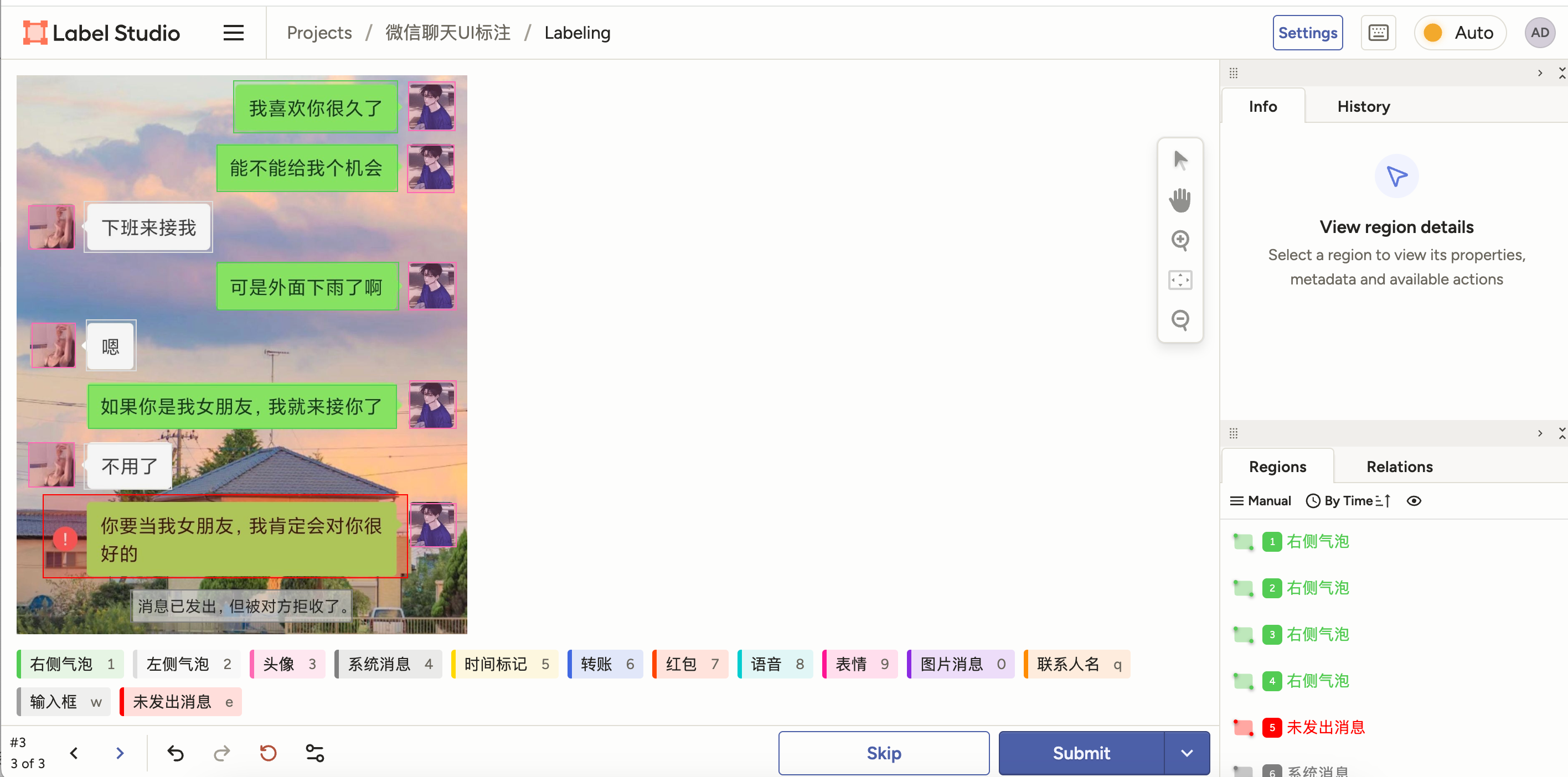
如果我打标100张图片,就可以训练出一个可用的模型,那完全可以尝试一下。
python3 scripts/04_train.py --epochs 100 --batch 8 --device mps第一次训练100轮:
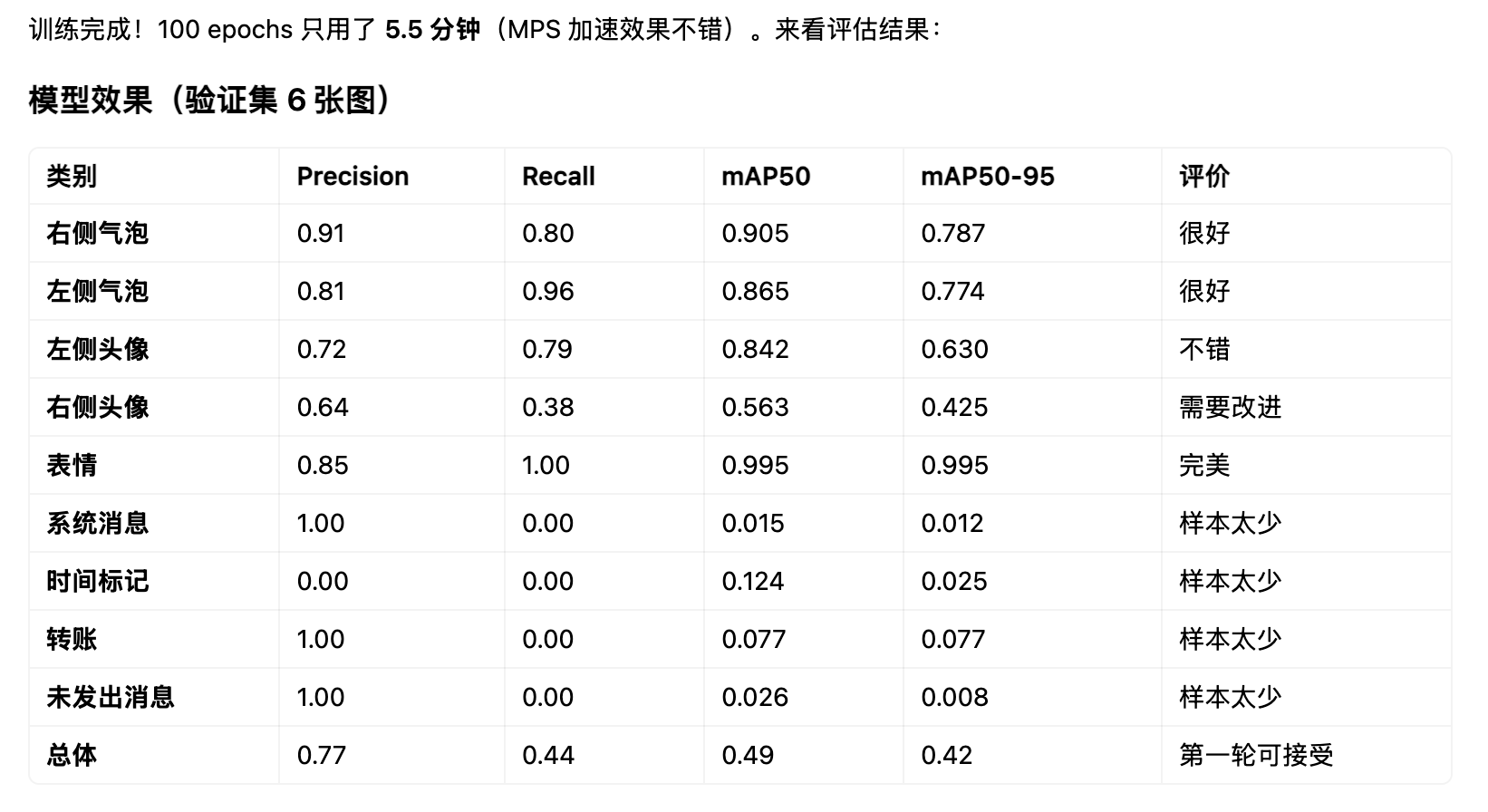
好消息:
- 气泡检测已经很好(mAP50 > 0.86),核心功能可用
- 表情检测完美(mAP50 = 0.995)
- 只用 30 张图、5 分钟训练就达到了这个效果
需要改进:
- 低频类别(系统消息、时间标记、转账、未发出消息)样本太少(各 1-2 个),模型没学到
- 右侧头像 recall 偏低(0.38),需要更多样本
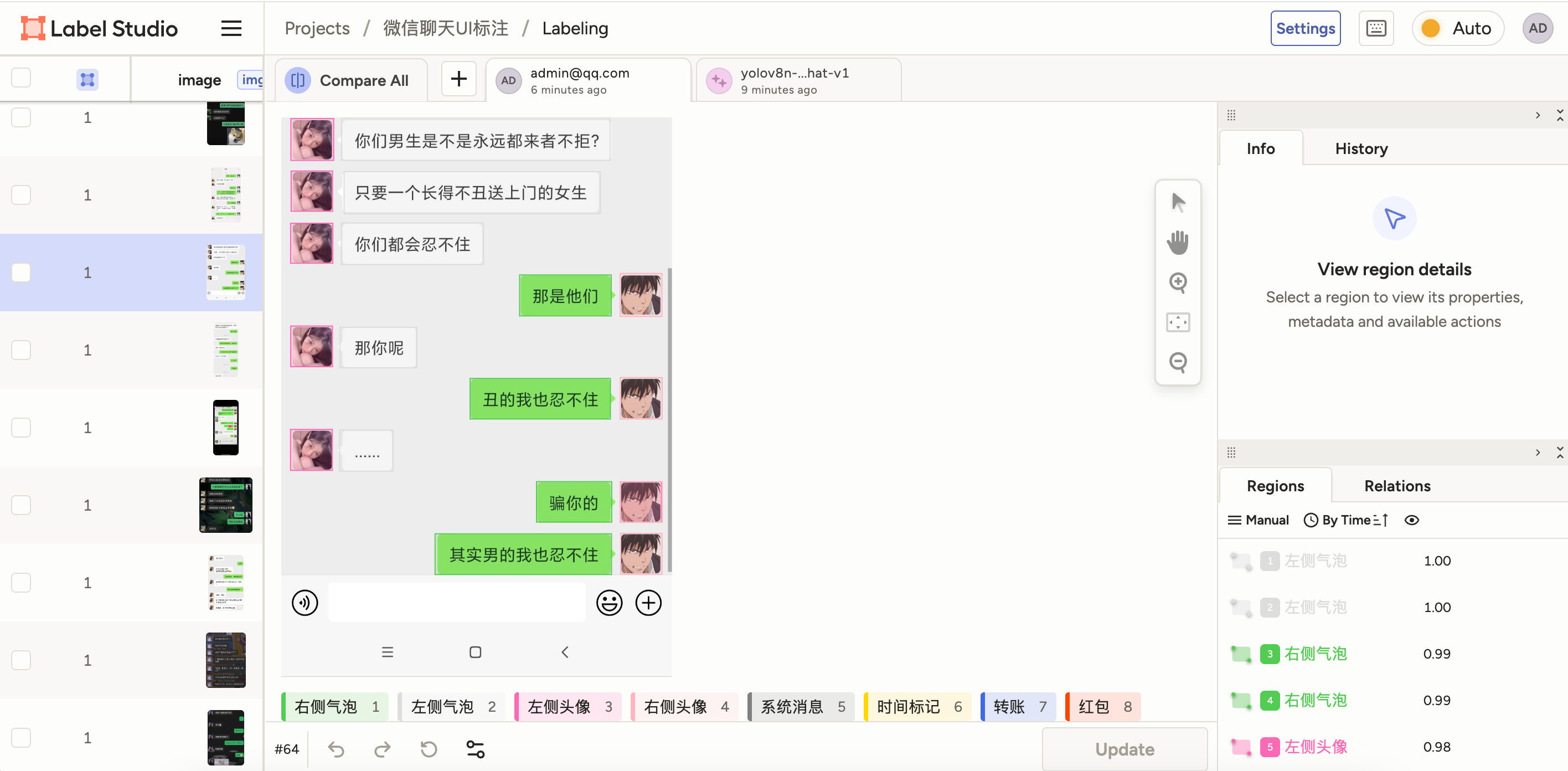
建议:现在可以用这个模型去预标注剩余图片,你只需要纠错,然后再训练一轮效果会大幅提升。
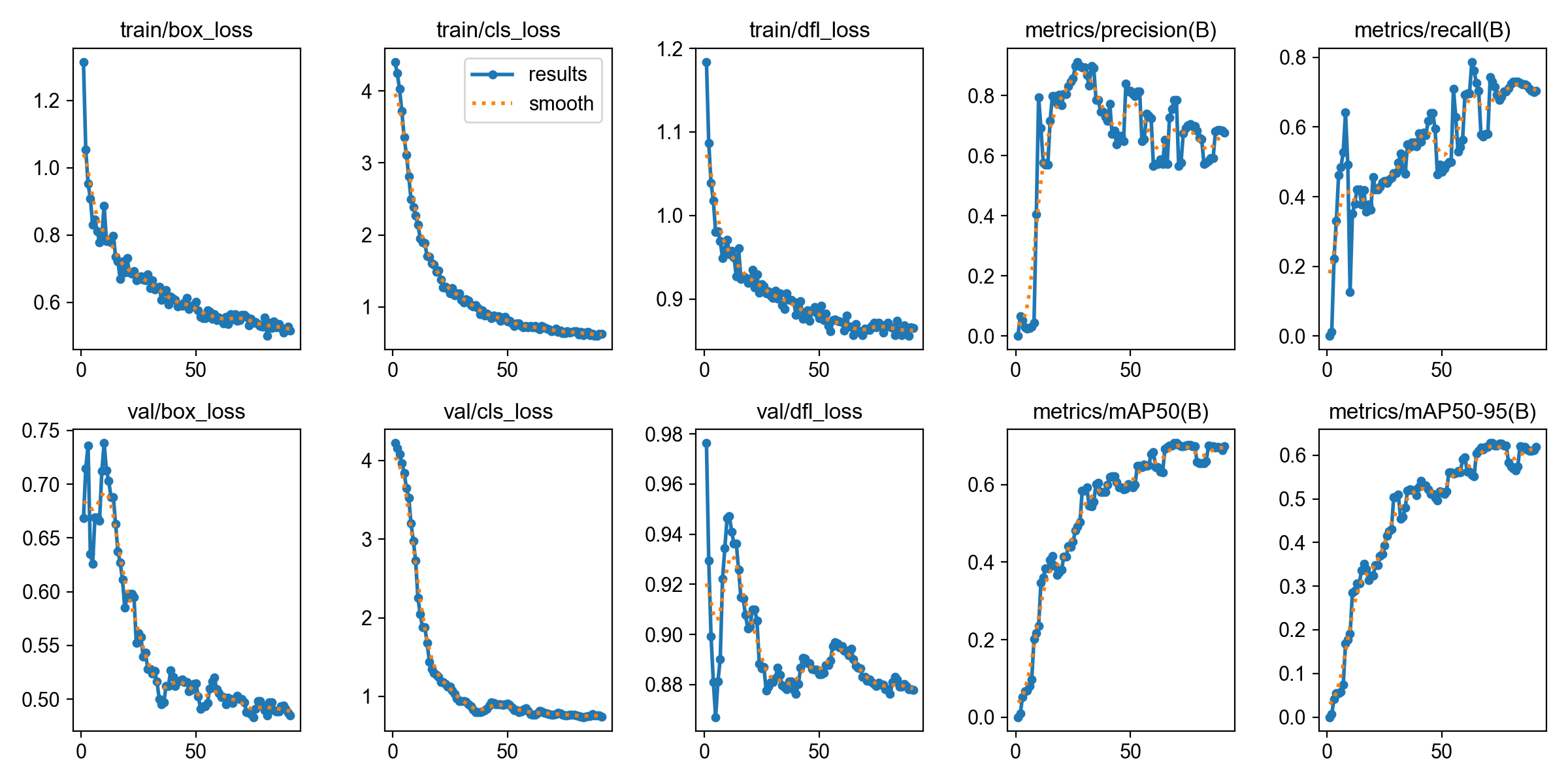
第二次训练:
训练已启动(150 epochs,batch=8,MPS 加速)。数据量翻倍+150轮训练,预计 10-15 分钟。
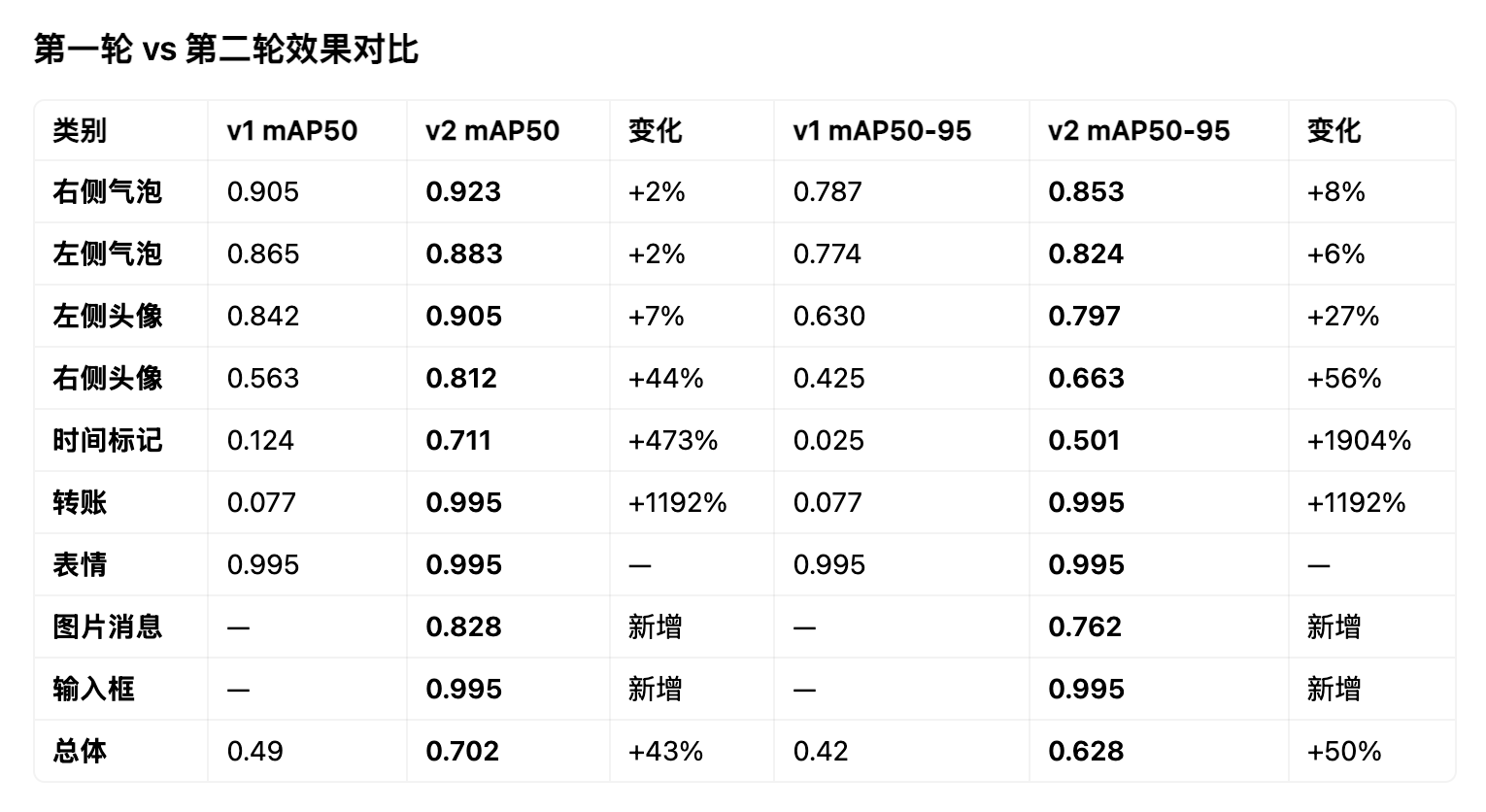
关键提升
- 总体 mAP50: 0.49 → 0.702 (+43%)
- 总体 mAP50-95: 0.42 → 0.628 (+50%)
- 右侧头像: 从 0.563 飙升到 0.812 (+44%)
- 时间标记: 从基本不能检测(0.124)到 0.711
- 转账/输入框: 直接到 0.995 完美检测
- 图片消息: 新增检测能力,达到 0.828
仍需改进
- 系统消息: 0.008(仅 7 个训练样本)
- 联系人名: 0.373(仅 19 个样本,需更多)
- 未发出消息: 0(仅 3 个样本)
测试一下: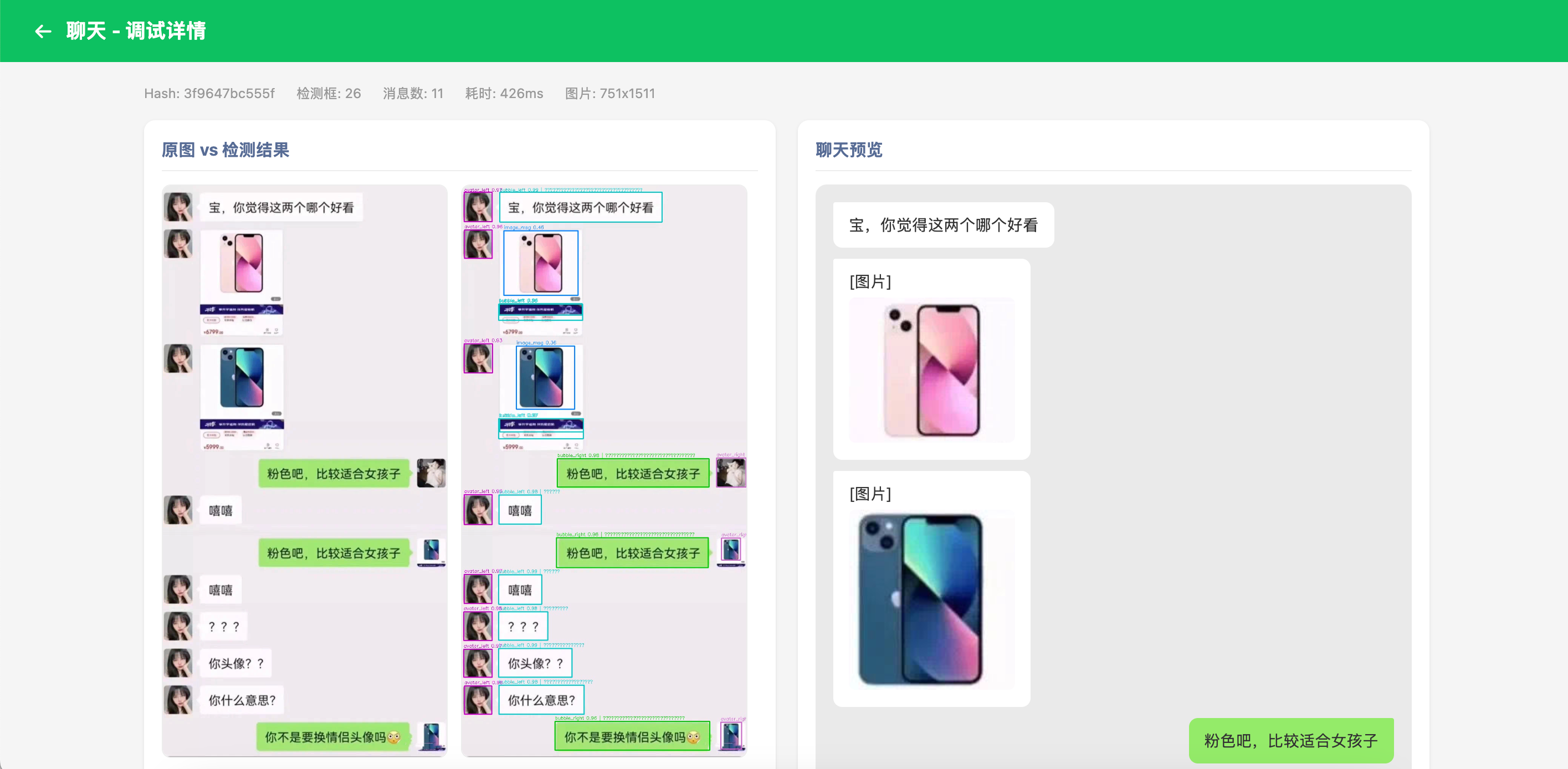
优化系统功能
一、打标系统
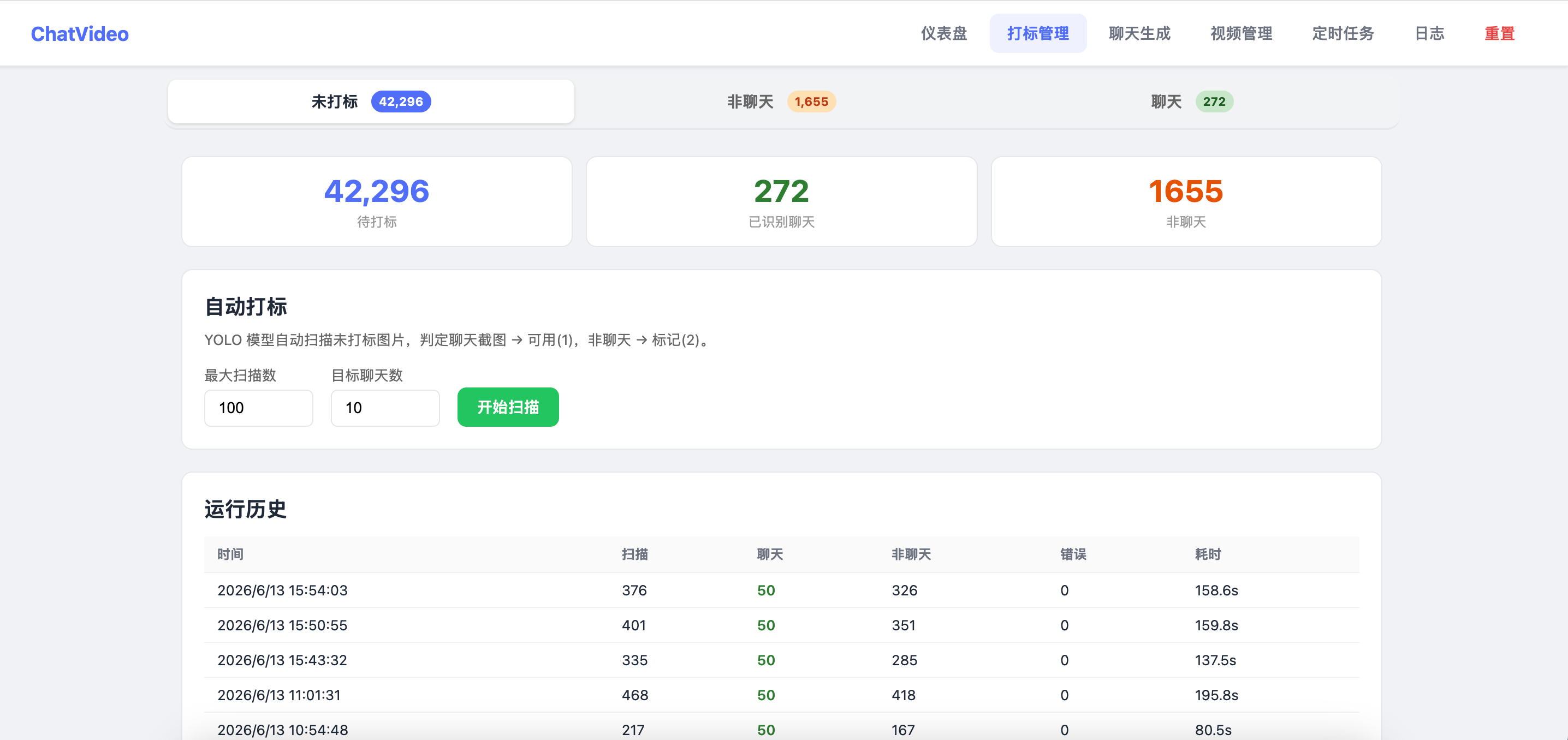
模型训练完成,开始改自己的系统;原本人工手动打标一页9张图的功能彻底删掉。现在使用模型完全可以自主根据特征判断该图片是否为聊天对话图片。前期误判的增加一个状态,后续继续放到打标平台重新打标签,优化模型,持续迭代。
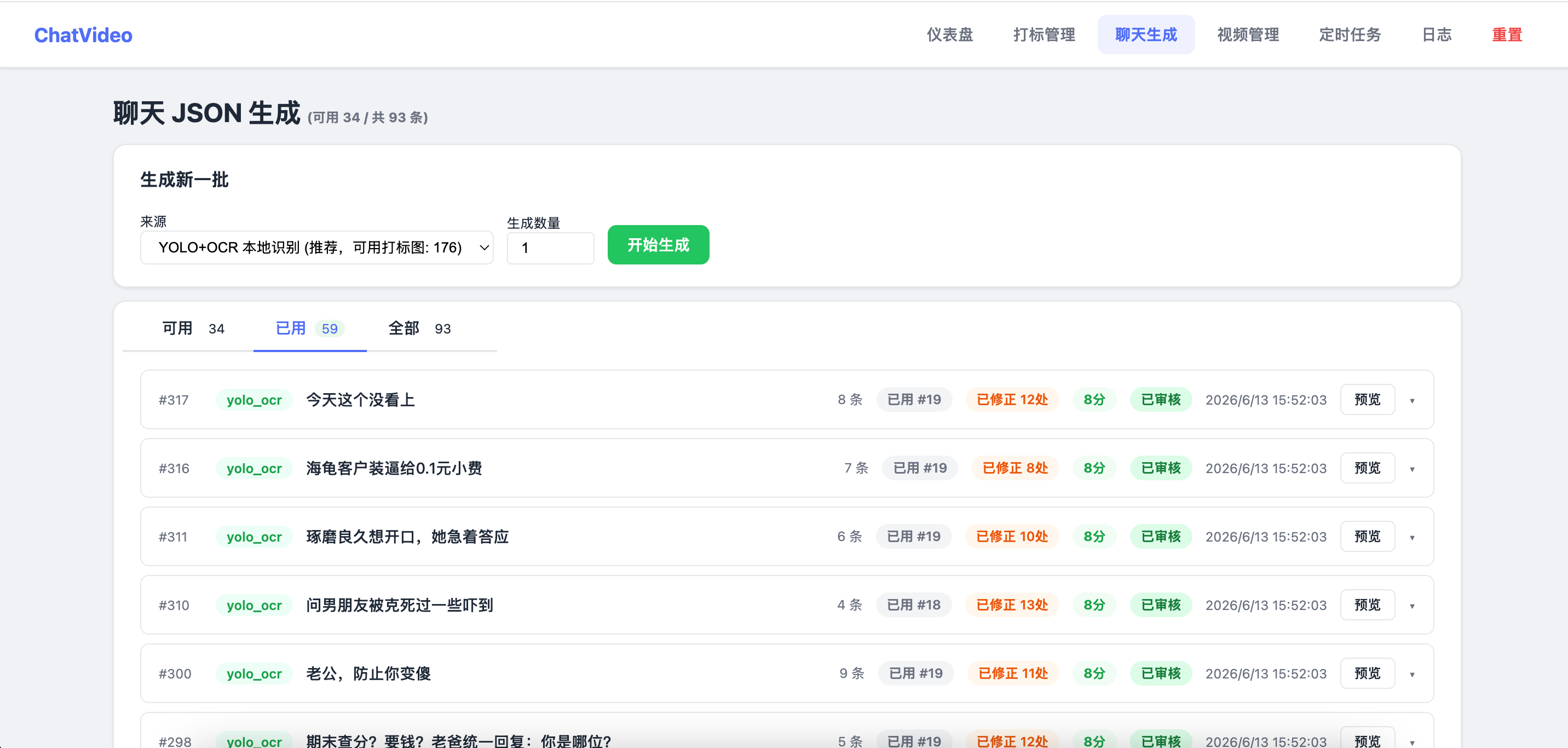
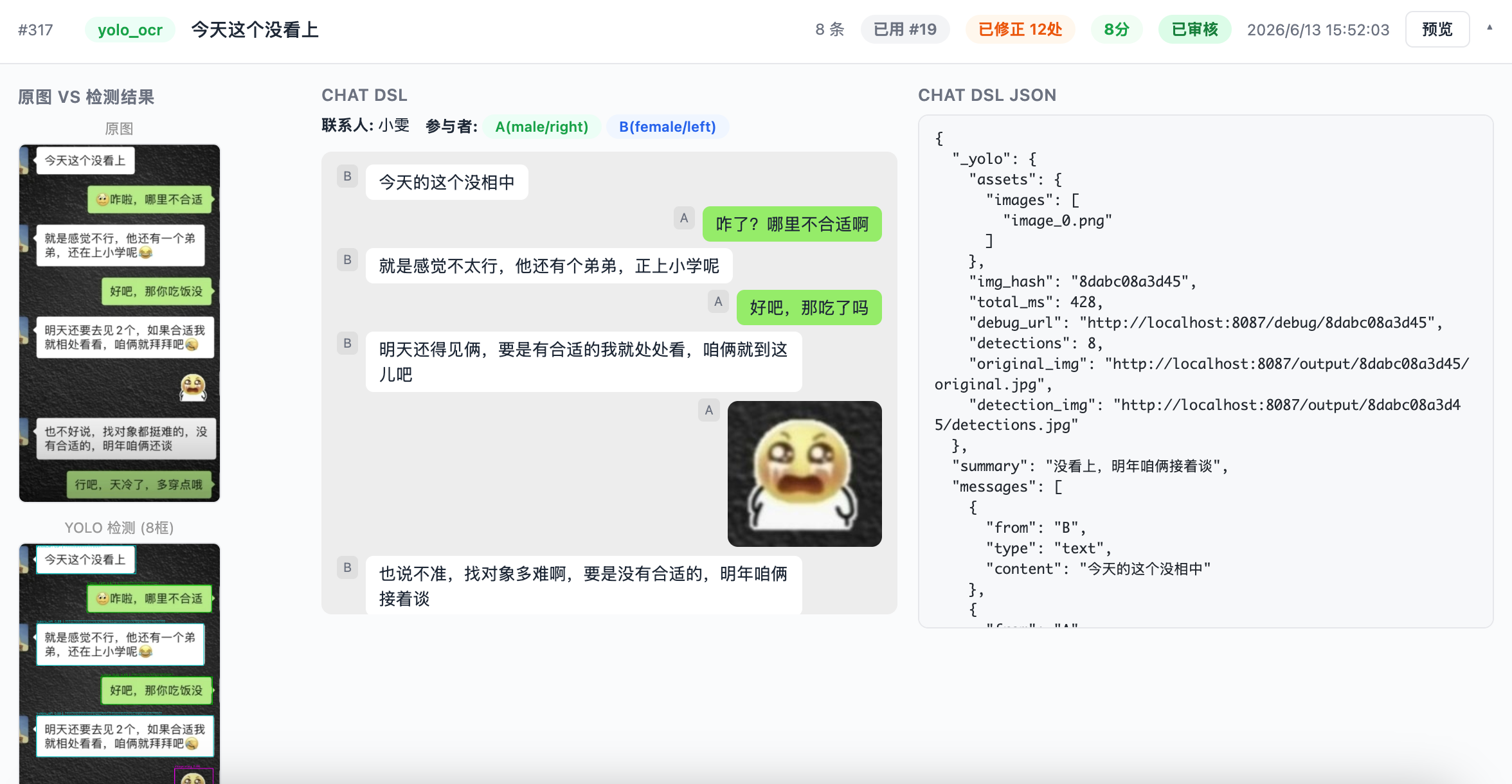
二、聊天生成
经过打标系统初筛的结果,作为聊天json生成的数据源,同样还是使用模型来识别,我把标签简化了一下,对话,图片(表情、图片、转账、红包)、系统消息、未发出的消息,等等,总之就是简化了标签;
这次最大的突破就是 deepseek-v4-pro 带来的,我写一个调优的定时任务,我理解我的调优任务一上线,所有对话记录全部重写,应该不会再被平台判定为非原创了吧。(洗稿可耻…凭技术洗稿还好吧,可以说是参考并重新创作。)
你是一个微信聊天记录校对专家。用户会给你一段从截图中 OCR 提取的聊天 JSON,
你的任务是检查并修正其中的问题,然后返回修正后的完整 JSON。
请检查以下几类问题:
1. OCR 错别字:
- 形近字误识别(如"已"→"己","未"→"末","人"→"入")
- 但要注意区分:故意的网络用语不算错别字(如"酱紫""8错""yyds")
2. 角色分配错误(A/B 颠倒):
- 检查对话逻辑是否通顺,是否有"自问自答"或"答非所问"的情况
- 如果发现 A 和 B 的消息应该互换 from,请修正
- side 为 right 的是"我",side 为 left 的是对方
3. 语义不通顺:
- 漏字、多字导致句子读不通
- 上下文明显矛盾(但要保留原意,不要过度改写)
4. 结构问题:
- time 类型消息不应有 from 字段
- voice/redpacket/transfer 类型应有正确的 params
- 检查 participants 的 side 和 gender 是否合理
返回格式要求:
严格返回以下 JSON 格式,不要加 markdown 标记或任何说明:
{
"issues": [
{"type": "typo|role|semantic|structure", "location": "第N条消息", "original": "原文", "fixed": "修正后", "reason": "修正原因"}
],
"fixed_dsl": { ... 修正后的完整 chat_dsl JSON ... },
"summary": "修正后的一句话摘要"
}
如果没有发现问题,issues 为空数组,fixed_dsl 返回原样。 把上述内容返回 markdown原文可复制的格式有一个问题:
minimax涨价了,原本29一个月,现在涨到49了,当然模型也升级到M3了,这就涉及到一个心理问题,原本按月买,敞开用,不用就亏,但是现在我买了deepseek的按量付费,同样我充 30 块钱,其实用不了那么多,但是总是要去关注账单,关注使用量,哈哈哈哈,这是什么心理小实验❓

三、视频管理
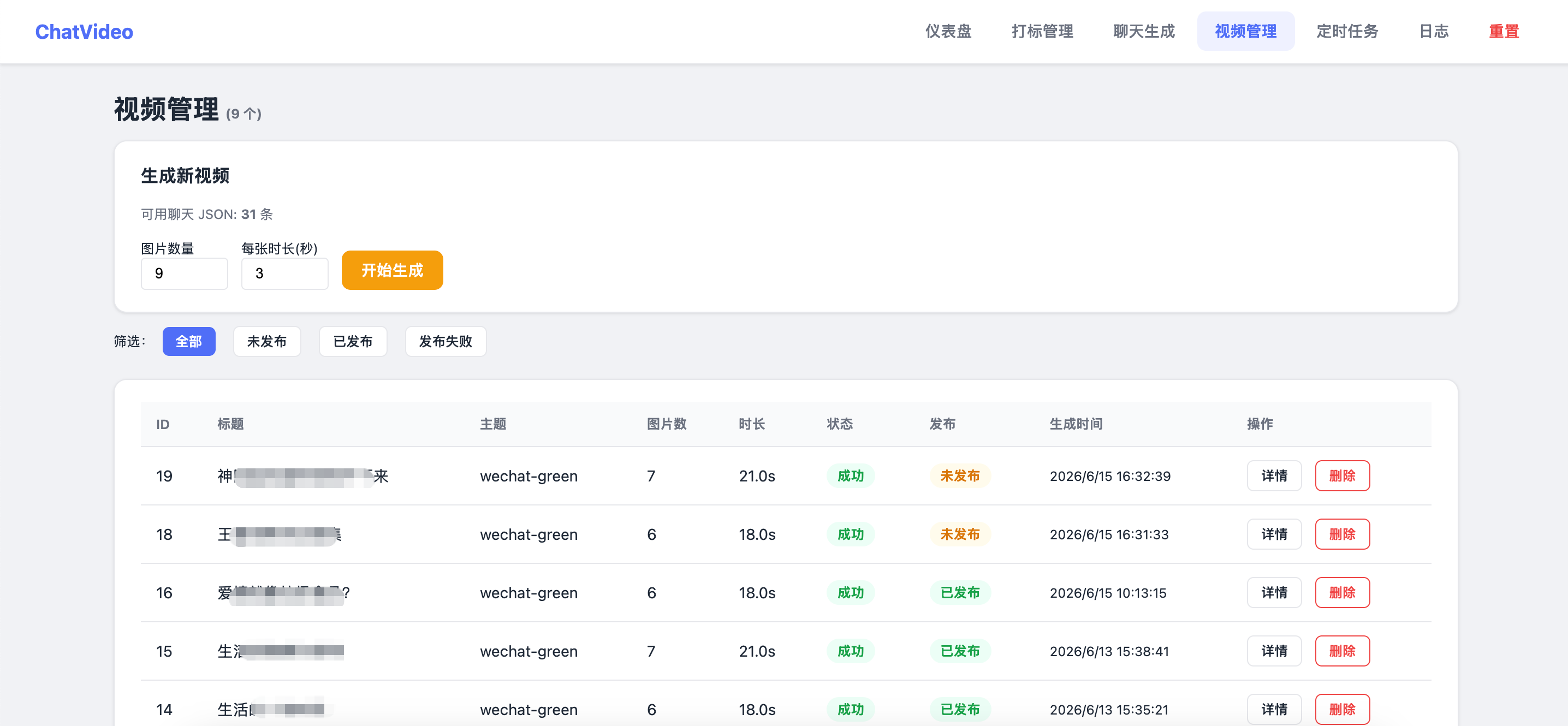
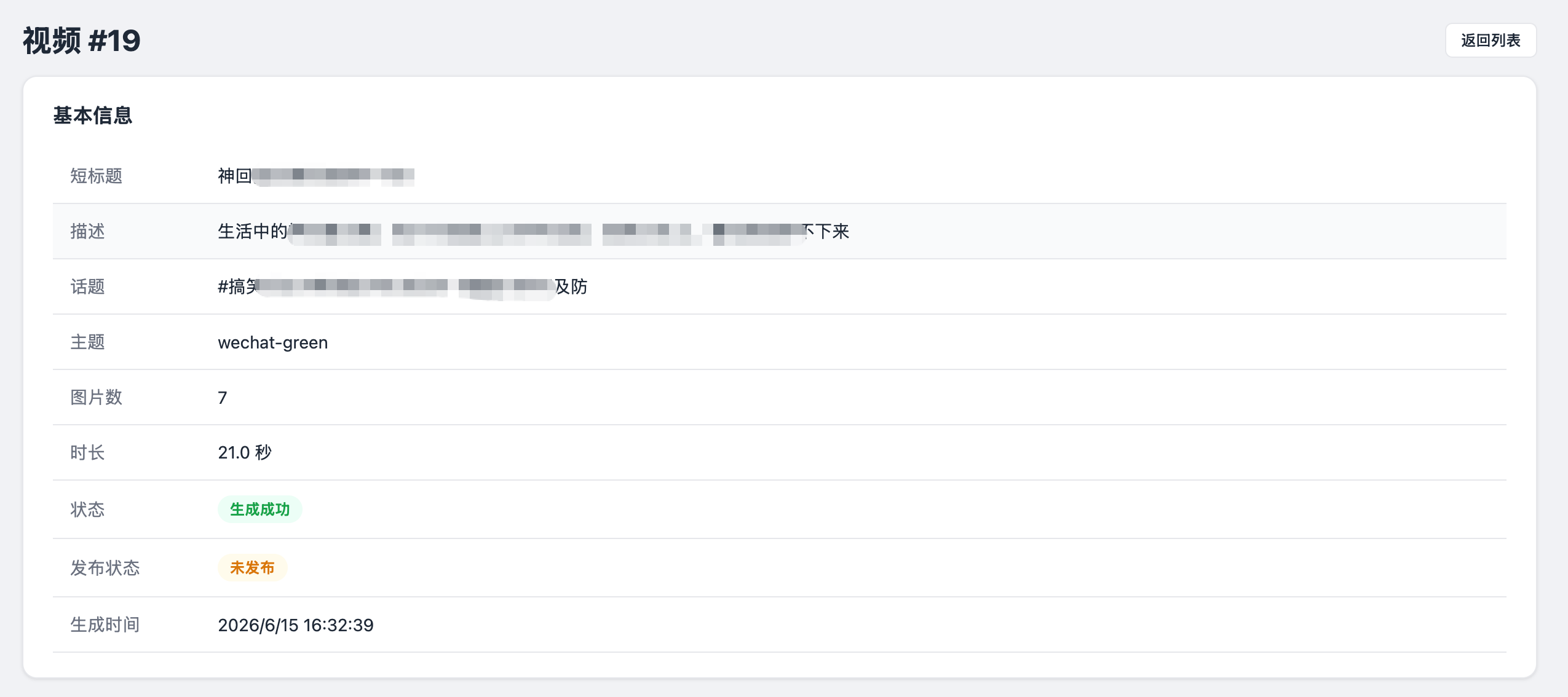
视频管理当然没有什么技术可言,就是图片+音乐合成视频,生成视频描述、短标题、标签,然后同样的使用脚本自动发布。
结束
最近差不多一个多月就在断断续续搞这个,事情太多了,不管是工作还是生活,跑一段时间看看吧,想想后面再搞点什么呢